

Most of the world thinks of WD as a hard disk drive (HDD) company. Inside our walls, we see things differently. We are a storage company, with HDD as our primary product.
In fact, in the early days of our 56-year history, WD was not a hard drive vendor. The initial flagship product of our company was in semiconductors, producing calculator chips. From there, the expansion moved into storage with floppy drive controller chips and then into hard disk drive controller logic. It may seem strange today, but in the 1980s, the HDD controller and the disk drive itself were two separate components. It wasn’t until 1988 that WD became a producer of HDDs.
Over these decades, what has been consistent is that we think about the architecture not just of magnetic media and HDDs, but of storage in general. What we see as we move into the AI-driven data economy is that as data infrastructure scales, architectures mature and evolve. With scale comes opportunity for differentiation. And that means that different workloads require different storage technologies; one size does NOT fit all.
AI workloads, inference systems, retrieval architectures, and persistent operational data are accelerating the need for intelligent tiered storage design.
The modern data center is tiered
Some in the storage industry will tell you that there is an existential “either/or” battle between SSD and HDD in the storage hierarchy. They believe storage is a zero-sum game. For one to grow, it must mean that others decline.
But the truth is that this is simply not how storage works at scale. The world’s largest storage consumers—hyperscalers—employ tiered storage strategies that balance the performance and total cost of ownership (TCO) needs of different workloads, placing data on the storage device that fits best.
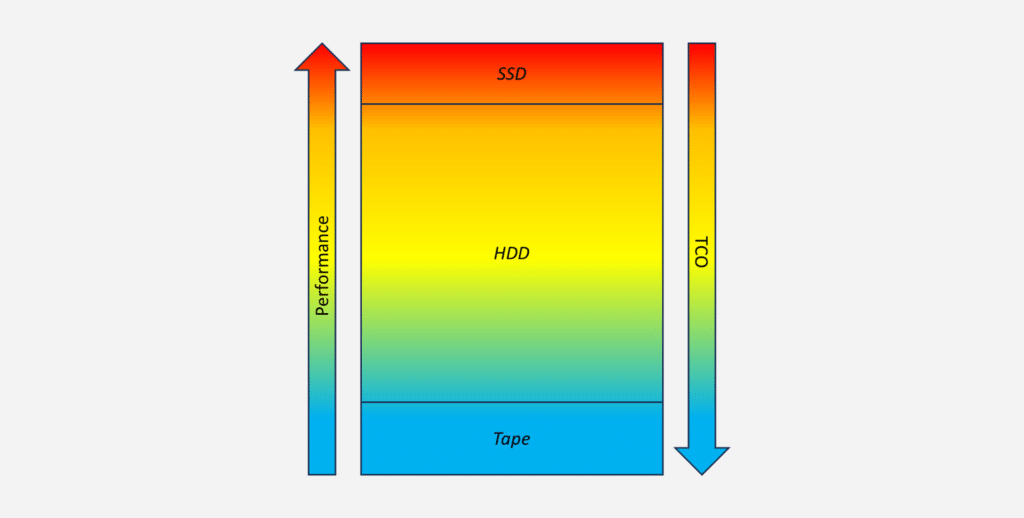
Not only is it not a battle between SSD and HDD, limiting the field to two participants completely overlooks the third major player in storage infrastructure: tape. To most, tape is forgotten. I think some were calling tape “dead” even before I graduated college. And yet it’s still a critically important business, comprising a little under 8% of worldwide installed cloud storage capacity in 2025.1
So rather than a fight between technologies, we see the data center market as picking the right tool for the right job. High-IOPS and low-latency applications should live on flash. Archival/regulatory/compliance data that must be stored but can handle hours-to-days retrieval time is perfect for tape. And pretty much everything in between lives on HDD—nearly 80% of the worldwide installed cloud data center capacity is HDD.2
At the system architecture level, when data storage volume is measured in hundreds of exabytes (EB) or even zettabytes (ZB), tiered storage is the way sophisticated companies ensure that both performance and cost efficiency are optimized. Nor is it a zero-sum game. Global data creation is forecast to rise from 218.4ZB in 2025 to 718.5ZB in 2030, more than tripling.3 Rather than fighting over a fixed demand, these technologies are vying for share of a rapidly growing pie.
AI infrastructure is further accelerating this shift. Modern AI systems continuously generate operational data that must be retained, retrieved, governed, and moved across different performance and persistence tiers over time. As AI scales, intelligent data placement becomes a core architectural requirement.
How tiered storage works
In previous eras, storage was tied to a single application, often in a single server, and served a single purpose. Even in “remote” storage such as NAS or SAN, where storage was disaggregated from compute, it was built to serve specific applications. Specific amounts of storage were provisioned for each application.
At scale, the architecture changes. Most storage at scale today is described as software-defined storage (SDS), where storage is generally considered to be a “pool” in which each application swims. Rather than devoting an Olympic-sized swimming pool to each application in case it needs it, the swimming pool can be dynamically provisioned only to give each application as many lanes as it needs in the moment. The scale allows optimization such that resources are allocated efficiently.
This scale also allows disparate storage technologies to be pooled such that applications with different performance requirements can exist in the same pool. Increasingly, retained data must remain retrievable long after the original workload completes, particularly in AI environments where inference, retrieval, fine-tuning, and governance workflows depend on persistent operational data. Some storage architectures utilize caching, where frequently accessed data is moved to hotter tiers such as flash, while cooler data remains on HDD. Other storage architectures define service-level agreements (SLAs) where certain high-performance applications live solely on flash, mainstream applications live solely on HDD, and cold/archival applications live solely on tape.
The SDS layer determines exactly where data must be stored for optimal efficiency. In a hyperscale data center, data is constantly moving and churning to be in the right place at the right time. At scale, tiered storage isn’t a theoretical concept; it’s an existent reality.
In modern AI environments, these decisions increasingly determine inference responsiveness, retrieval performance, GPU efficiency, and long-term infrastructure economics.
Where WD fits in the tiered storage hierarchy
While we internally think of WD as a storage company, our core product is unmistakenly HDDs. HDD infrastructure remains the dominant (nearly 80%) capacity foundation for hyperscale data environments globally. HDDs offer a compelling balance of capacity, performance, and TCO. The primacy of HDD as the dominant storage technology in the modern data center is not expected to change. The commitment to advancing HDD technology and capacity is the cornerstone of our business.
That said, we are not limited to only HDD. WD enables the tiered storage ecosystem in the following ways:
- WD, through our Data Center Platforms group, produces the OpenFlex Data24 storage system, a 2U24 ethernet bunch of flash (EBOF) utilizing NVMe-oF™ connectivity to 24x U.2 NVMe™ SSDs. These are direct ethernet-attach flash systems offering high performance and composability for dynamic provisioning.
- The Platforms group offers the RapidFlex series of fabric bridge adapters that are initiators and targets for NVMe-oF. These components help customers transition to NVMe-oF architectures smoothly.
- The Platforms group also hosts the Open Composable Compatibility Lab (OCCL), which provides testing across disaggregated compute, storage, and networking—delivering validated reference designs that span needs across the AI data lifecycle and accelerate innovation and time to market.
- Within the HDD tier, we announced at Innovation Day 2026 the development of high bandwidth drive technology (HBDT) and dual pivot, which will increase HDD performance to levels never before seen while maintaining HDD economics, extending HDD’s reach in the warm tier of storage. In addition, we announced the development of power-optimized HDDs, which will offer better TCO and capacity for online archival storage, while only seeing minimal performance loss compared to today’s nearline HDDs. Much like the flash industry offering both TLC and QLC options based upon workload and application needs, performance- and power-optimized HDDs will expand tiers within tiers for the tremendous portion of the data center where our products live today. As AI infrastructure matures, storage hierarchies themselves are becoming more specialized4, with different tiers optimized for inference responsiveness, persistent operational retention, archival durability, and long-term economics.
- But it extends beyond HDD and flash. In an important but little-known part of WD’s business, WD has leveraged our expertise in magnetic recording to be a supplier of read-write heads to the tape industry. This helps enable the cold/archival tape tier of storage.
- Finally, in addition to our Platforms team offering high-density HDD storage products such as the Ultrastar Data60 and Data102 JBODs, we also announced at Innovation Day the ongoing development of an open API allowing customers to integrate flash and HDD under a common architecture, making storage tiering easier and accessible to all. This not only helps customers architect for HDD, it also helps them architect for flash where it is needed.
Some might look at these activities and ask why we’re enabling our competitors. That question assumes the “either/or” framing that one storage technology must dominate all others. WD rejects that framing. We view tiering as the natural evolution of storage. We’re not fighting it; we’re participating in all tiers, where and when we can add value.
Tiered storage is the present for hyperscale, and the future for others
Today, tiered storage is a reality at scale. Hyperscalers already embrace it. With the amount of data they have under management, it’s the only architecture that makes sense.
AI infrastructure is no longer simply a compute environment attached to storage. Increasingly, it behaves as a persistent data system where information continuously moves across performance, capacity, and retention tiers throughout its operational lifecycle.
For those who aspire to grow their scale, such as neoclouds, it’s important to think about the architecture of the future, and how to afford it. The economics of storage can’t be ignored. The answer is rarely “all flash” or “all HDD”; it’s a tiered mix. Getting the mix or the architecture wrong results in either wasted money or inadequate application performance. For a cloud service provider trying to satisfy customers, either outcome is bad for business. Locking into a sub-optimal architecture because it wasn’t considered up front is an expensive thing to reverse after the fact.
The message to these emerging scalers is clear: the infrastructure decisions emerging scalers make today will define not only their future cost structure, but also their operational flexibility, inference scalability, and ability to sustain long-term AI growth economically.
- Source: Pivot Table: IDC Global StorageSphere Forecast, 2026–2030, #US54601626 June 2026
- Source: IDC Revelations in the Global StorageSphere, 2025, August 2025
- Source: Pivot Table: IDC Global DataSphere Forecast, 2026–2030, #US54587626 June 2026
- Silvia, Joshua. “Tiered storage for AI: scalable performance and cost control.” Solved Magazine. https://www.solved.scality.com/tiered-storage-for-ai-scalable-performance-and-cost-control/

