
An overview of computational storage
Analysts estimate that by 2025, 463 exabytes of data will be generated every day globally. At the same time, more cases for real-time analytics and data processing are emerging. To address this need, consumer and enterprise businesses are seeking a radically simple approach: moving computation and storage closer together, referred to most often as computational storage.
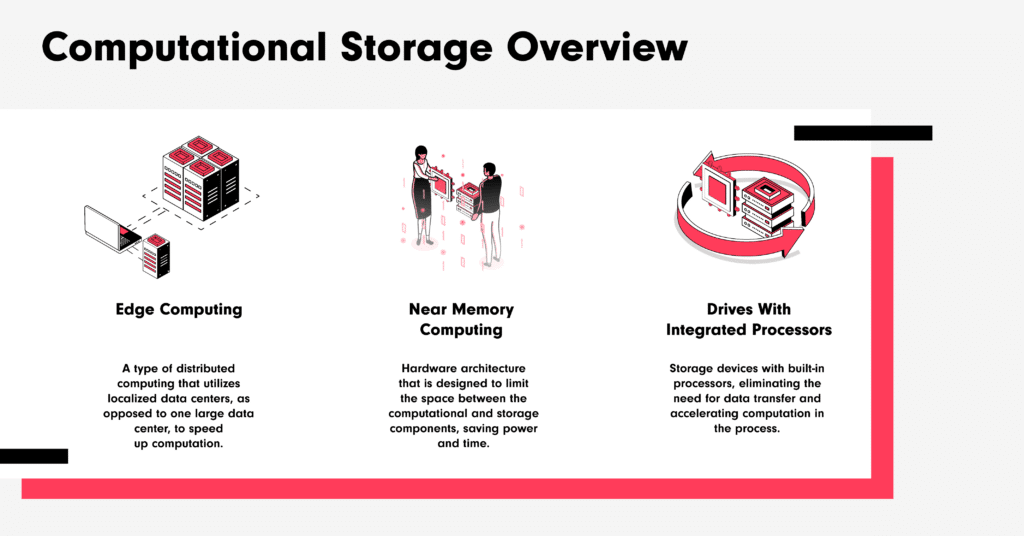
Computational storage is a technology that seeks to analyze and process data where it resides, typically in storage devices like HDDs or SSDs. The goal is to accelerate the rate of data processing, while limiting the need to transfer data from location to location, a slow and costly endeavor.
While the concept has a simple purpose and explanation, computational storage is also an umbrella term. Various combinations of technologies today are trying to address the issue of moving data and how to speed up analysis, and computational storage groups them all together. The complex networking and hardware solutions for enterprise and consumer-focused products, like self-encrypting storage devices, are both examples.
To better understand the importance of the technology today, here are the most common forms of computational storage, starting with those large-scale solutions and moving downwards to the smaller implementations.
Edge computing
Edge computing is the most blended and interdisciplinary example of computational storage, one which blends network and storage solutions to improve performance and reduce latency. It’s an example of physically moving compute and storage together — over miles, not microns. Edge computing seeks to solve the problems of speed and cost by eliminating the need to send data to a central data center. Instead, data is sent to one of many localized data centers for faster service and analysis. The “edge,” in this case, refers to a geographic location: the edge of the localized data and the cloud.
While the edge blends many technologies together, Wim De Wispelaere, VP of corporate strategic initiatives at Western Digital, sees it as a quintessential example of computational storage. He says that there are “common themes,” with edge and computational storage and that they all “fall under the same category of distributed computing.”
The benefits of edge computing become evident when thinking about the challenges of moving large amounts of data. Due to the size of files and the limitations of stable internet access around the world, some industries find it’s faster to physically move the data from one location to another. With the power of edge computing, the data can travel a shorter distance, be analyzed, and save any large travel efforts for only the results. For teams conducting research in remote locations, the edge enables discovery, testing, and evaluation at previously unattainable speeds.
Pushing computer and storage closer together
The next example of “computational storage” involves physically placing the computation and storage components in data centers closer together. Sometimes referred to as “near memory computing,” the idea is to reduce the travel time of the data, cuts costs, and improve output. This is accomplished through architecture that rearranges and prioritizes the proximity of computation and storage, either through directly linking the two or through the use of logic and code to assist the system in managing workloads.
While these designs can save on latency, their benefit is ultimately power and time efficiency. As Marc Staimer, an analyst and principal at Dragon Slayer Consulting said in an interview, “the challenge lies in shortening that access time and reducing the power needed to acquire the data.”
The most relevant use cases for near memory computing are in artificial intelligence and machine learning. While the repetitive tasks of machine learning algorithms aren’t the most intensive, they are frequent. As a result, moving the two together saves costs. Efficiency is the name of the game in machine learning. Freeing the algorithms from access time and power concerns enables the technology to learn faster, resulting in better performance and new developments in automation, research, and service.
Drives with integrated processors
Finally, the most on-the-nose interpretation of computational storage: storage devices with built-in processors. Moving the two aspects of computing as close as they can get nearly eliminates the need for data transfer and enables the system to immediately begin its work. Instead of requesting blocks of data and waiting, a computational storage device just requests the operation to be run on the accessible data. This solution addresses cost efficiency and prioritizes speed. When data and processing share space, devices can process data and respond like never before.
Drives with on-board processing units address the shortage of memory available for computation in devices or systems that have other tasks to manage. Instead of having to crunch the numbers with the primary processor, the computational drive’s rapid access to the data enables it to create subsets of data, which are more manageable for AI to interpret and faster to transfer to a centralized data center for further analysis.
Vehicles are one of the main benefactors of this implementation. Cars have so many sensors and capture devices embedded in them that we cannot yet capture and analyze their wealth of data. Especially in the developing autonomous vehicle market, there is a need for rapid telemetry data capture and analysis, a task that computational storage devices are uniquely positioned to solve. Their rapid data access can keep passengers safer and empower manufacturers to gather more insights to improve their autonomous systems. These devices might even be able to further accelerate the birth of smart cities, where all sorts of devices converse to improve the quality of life for residents.
Closer to data
While those are just three of the many examples of the umbrella term computational storage, they all highlight the same simple concept: bring processing and data together. In the hyperconnected information era, that union seems more important than ever, too.
As De Wispelaere put it: in the future, “data will figure more into our lives than ever — and make our lives more enjoyable than ever.”

