

[Tweet “#Bigdata is the digital gold – but first you must overcome its challenges. #Hadoop”]
Big Data is the digital gold. Considering the opportunity and value at stake, organizations can’t afford to ignore the benefits of implementing Big Data. Finally, companies can leverage data that is spawned across a multitude of business silos (whether divisions, geographies, or functions) to answer a new range of queries and optimize business processes through analytics, rather than depend on executive intuitive judgment. What’s especially exciting is that Big Data has the potential to revolutionize and drive every aspect of industry verticals like manufacturing, retail, financial services, transportation, and healthcare. The potential and opportunities are enormous!
Challenges on the Big Data Journey
While there is no doubt that Big Data can provide substantial benefits to businesses, organizations trying to embark on the Big Data journey are more than often confronted with challenges. Our own Chief Data Scientist, Janet George, recently discussed some of these. On the infrastructure end, integrating Big Data technology with existing infrastructure proves difficult due to the need to massively scale at efficient economics, challenges of deployment and management, and a need for faster storage to meet Big Data processing demands.
To add to the difficulty comes the fact that not all data created is ‘equal.’ Some data needs to be accessed in real-time to derive business value. With the growing volume of data it is essential to differentiate and extract real-time information for making real-time business decisions. The rise of Apache Spark for real-time analytics is a great example of how fast data is gaining great importance.
The figure below shows the Big Data processing architecture and the key challenges for implementation:
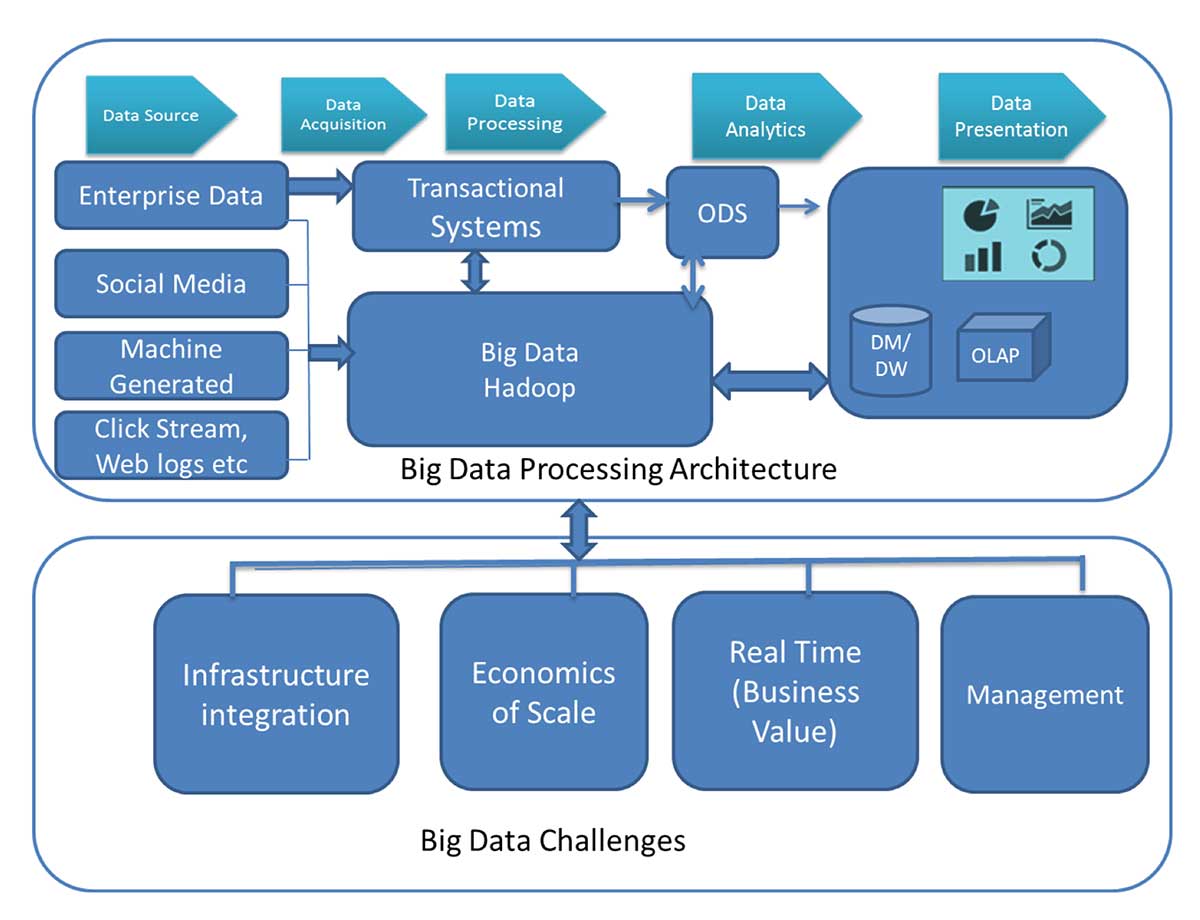
As companies prepare to build a Big Data Hadoop solution stack they need to consider the solution carefully in order to effectively mitigate these challenges. I want to describe a new solution we’ve been testing that can deliver these critical advantages.
Testing the Big Data Hadoop Solution Using Cisco UCS Servers and Fusion ioMemory™
For this solution, we built a stack using Cisco UCS B200 blade servers using the UCS 5108 blade server chassis and Fusion ioMemory PCIe application accelerators from SanDisk®. All of the Hadoop data communication was managed by the Cisco UCS 6300 fabric interconnect.
The Cloudera Hadoop distribution was employed on this infrastructure stack consisting of one dedicated master node and seven data nodes. The Hadoop replication factor was configured at the default of three; all the standard hdfs and map reduce configurations were utilized for a baseline setup.
The figure below shows the solution architecture setup:

The Hadoop distribution comes with various benchmarking tools to evaluate the performance of the Hadoop cluster. Hadoop performance benchmark tools like DFSIO and TPCx-HS were executed to evaluate the performance of the combined solution stack. I’d like to share some of the results with you.
fio Read and Write Throughput Charts
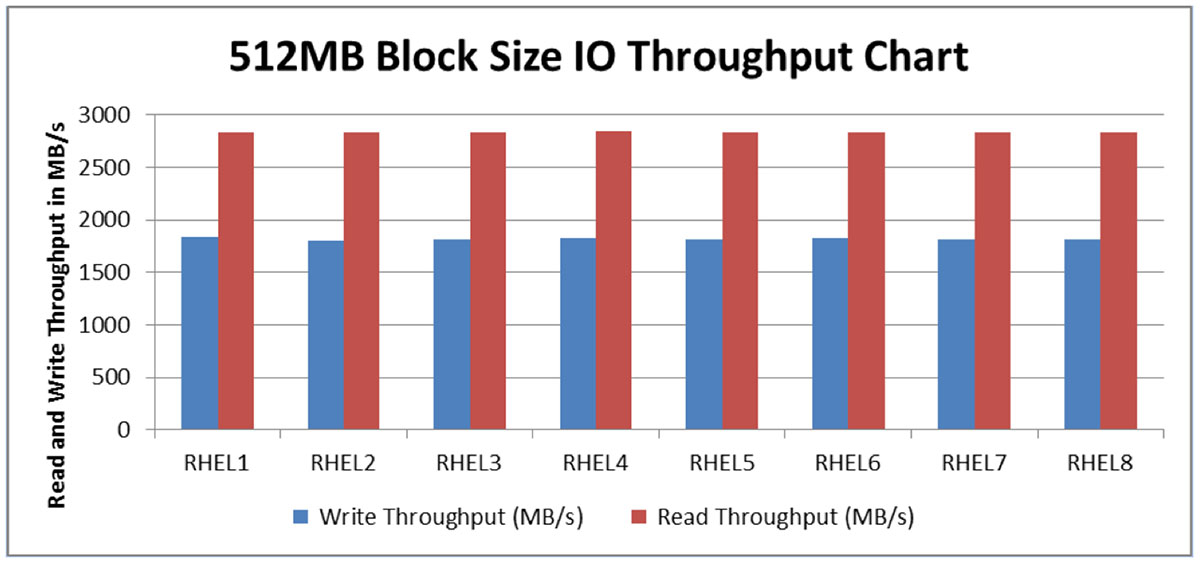
Prior to evaluating Hadoop performance, we decided to assess the raw system and storage performance. We employed a standard FIO tool to measure raw disk write and read performance. Since Hadoop clusters experience large block sequential write and read workloads, the fio script is designed accordingly to evaluate these.
The chart below shows the outcome of the sequential read and writes workloads. (All eight Cisco B200 blade servers were loaded with the Cisco Storage Accelerator). It shows that on average, each server delivered sequential read throughput of 2.8 GB/s and sequential write throughput of 1.8 GB/s.
Distributed File System IO (DFSIO) Benchmark
The DFSIO benchmark measures average throughput for read and write operations. DFSIO is a MapReduce program, which reads/writes data from/to large files. Each map task within the job executes the same operation on a distinct file, transfers the same amount of data, and reports its transfer rate to the single reduce task. The reduce task then summarizes the measurements. The benchmark runs without contention from other applications, and the number of map tasks is chosen to be proportional to the cluster size. It is designed to measure performance only during data transfers, and excludes the overhead of task scheduling, start up, and the reduce task. DFSIO has to be executed in two phases, first the DFSIO benchmark write creates the write-intensive workload by creating large numbers of files on the Hadoop cluster and the DFSIO read benchmark reads these files and creates the read-intensive workload.
The DFSIO write benchmark involved creating a 1 TB dataset with 192 files, each file with 5.4 GB of storage. The Hadoop replication factor was configured to the default of three, so with three-way replication the total dataset generated was 3 TB.
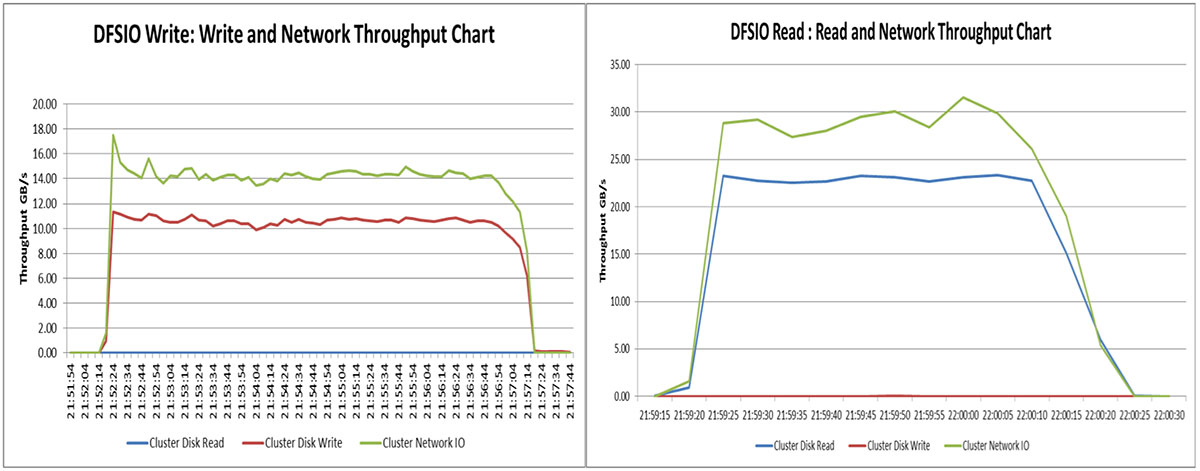
As you can see in the charts, the total time needed to generate the 1 TB of test data and replicate it three times was just under 300 seconds. The DFSIO-Read benchmark is a read-intensive test, reading the corresponding files that were generated by the DFSIO write workload. This read benchmark test initiates 192 map jobs to read 192 files. The TestDFSIO read benchmark finished under 60 seconds.
Here are the key takeaway points:
- The DFSIO write performance test generated an average of 10.15 GB/s write throughput and 13.7 GB/s of average network I/O throughput. This uniform performance throughput indicates the cluster write throughput for write intensive workloads like data loading, data ingestion etc.
- The DFSIO read performance test generates an average read throughput of 15.72 GB/s and average network I/O throughput of 19.67 GB/s. The performance metrics help to evaluate the read throughput of the cluster for executing Big Data analytics jobs.
Measuring Performance with the Application Benchmark Suite (TPCx-HS)
TPCx-HS is the industry’s first standard for benchmarking Big Data systems. It can be used to assess a broad range of system topologies and implementation methodologies, in a technically rigorous and directly comparable, vendor-neutral manner. While the modeling is based on a simple application, the results are highly relevant to Big Data hardware and software systems.
This benchmark is executed in three phases:
- HSGen generates the test workload and replicates it three times to all data nodes of the cluster. This workload determines the disk writes and network performance throughput of the Hadoop cluster.
- HSSort samples the input data and sorts the data. The sorted data must be replicated three ways and written on a durable storage. This workload evaluates the CPU and disk performance for sorting and merging.
- HSValidate verifies the cardinality, size, and replication factor of the generated data. This phase evaluates the network and read throughput performance of the Hadoop cluster.
The workload we used in this experiment was based on TPCx-HS but not audited or published. No comparisons were made with published TPCx-HS results. The run report shows the duration of execution for various phases of the test.
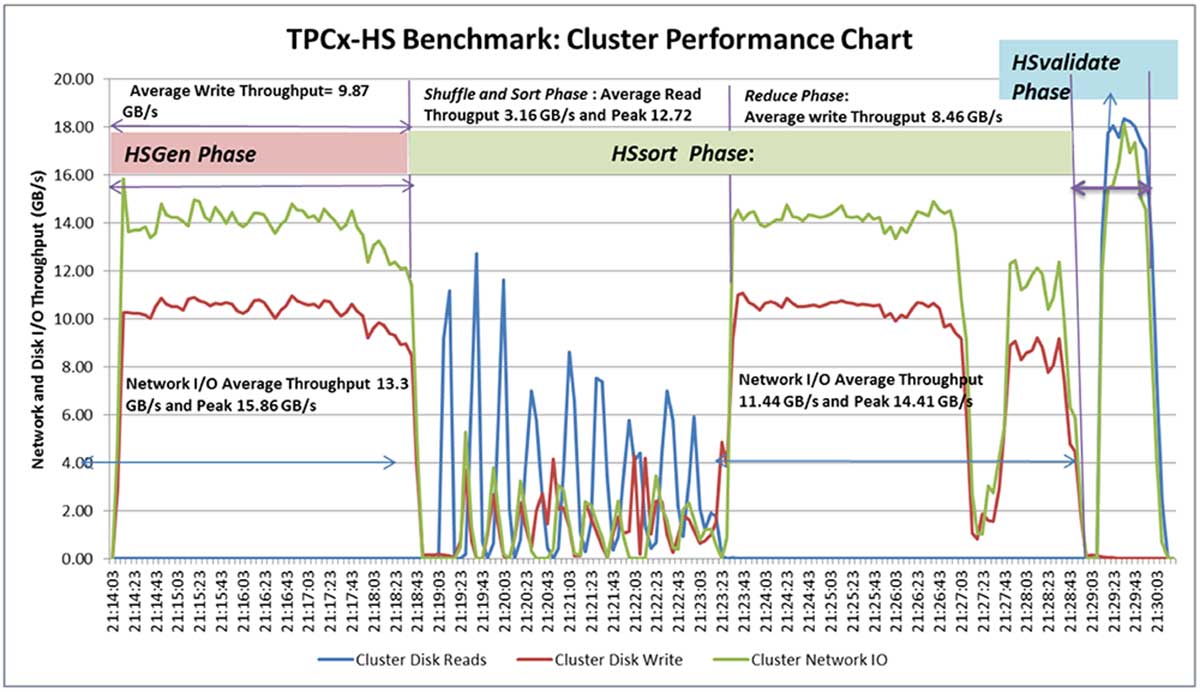
As shown in the chart below, the 1 TB dataset benchmark completed in under 13 minutes. During the HSGen phase the Hadoop cluster experiences the write-intensive workload and the Hadoop storage powered by Fusion ioMemory devices were generating an excellent average write throughput of 9.87 GB/s with the Cisco fabric interconnect network delivering average network throughput of 13.3 GB/s.
Also in the chart is the HSSort phase. HSSort is a CPU-intensive workload to sort all the data keys, only the data keys which are not sorted in memory spill over to the disk. The configuration parameters, like sort.io.mb and JVM (mapred.child.java.opts), help to optimize the HSSort execution. These data keys need to write output to a Hadoop file system and this is a function of the reducer phase of the map reduce application, also a write-intensive workload like HSGen phase.
This Hadoop cluster was generating an average write throughput of 8.47GB/s. Network throughput complemented faster storage by generating 11.44 GB/s to make sure these Hadoop blocks replicated efficiently to the required nodes of the cluster.
The benefit of the faster storage using Fusion ioMemory is clearly highlighted not only during the HSGen phase and the HSSort reduce phase – for supporting write intensive operations – but also during the HSSort shuffle and sort phase for faster sorting operations. Overall, Fusion ioMemory helps to accelerate the TPCx-HS benchmark suite and highlights how a high-performance stack employing faster servers, storage, and network can deliver faster analytics via Hadoop.
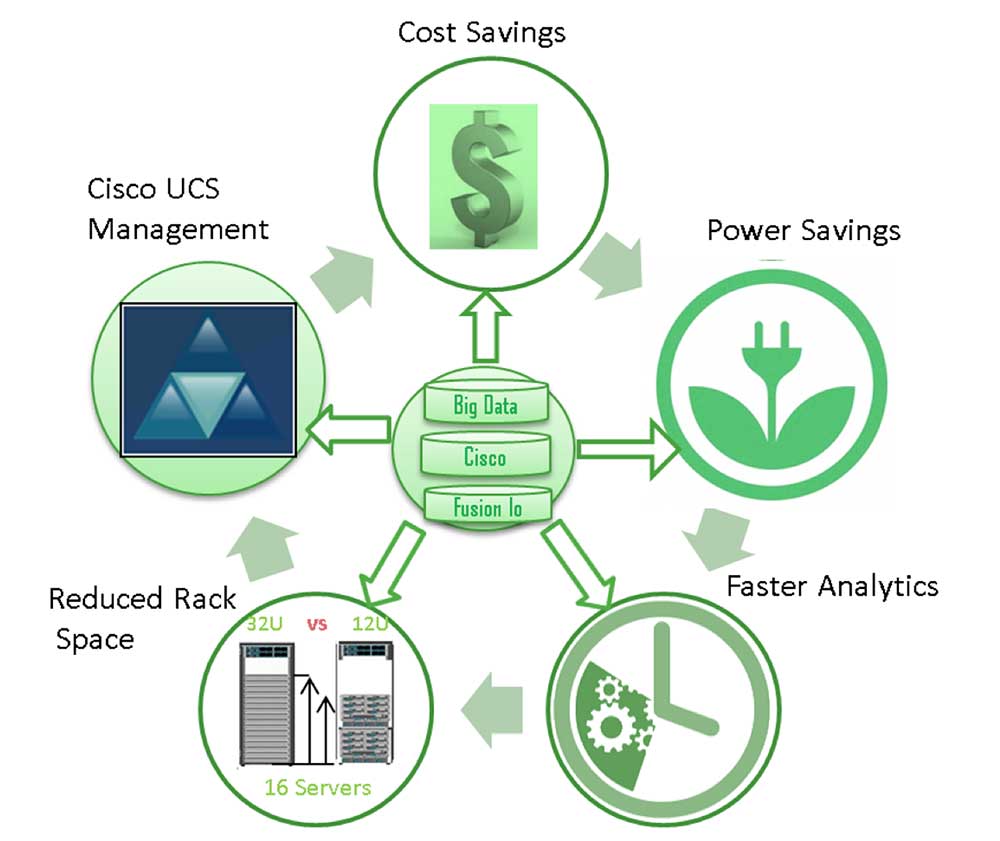
Solution Benefits
Using the Cisco UCS blade server with Fusion ioMemory storage for Hadoop applications has many benefits, through unique hardware features and as shown by our testing results. Here’s a short overview of what you should keep in mind:
- Cisco UCS policies can be customized and automated for large-scale and rapid Hadoop deployment. This saves significant time and effort and improves operational efficiency.
- The Cisco UCS blade server with Fusion ioMemory from SanDisk saves significant rack space, thereby increasing Hadoop cluster density.
- The solution provides savings in power and cooling costs compared to traditional rack servers containing many hard disk drives.
- A fault-tolerant Cisco hardware stack, improved operation efficiency for Hadoop deployment, rack space savings, and reduced power and cooling requirements all reduces the customer total cost of ownership (TCO).
Conclusion
Big Data and Hadoop are having significant impact on businesses. The pace of adoption poses challenges for organizations when seeking faster time to value, integration with existing infrastructure, management and operation efficiency, and cost of implementation. Our solutions utilizing Cisco UCS servers together with Fusion ioMemory from SanDisk benefit Hadoop cluster deployment by delivering improved operational efficiency and faster analytics with millisecond latency –at a lower cost. This solution stack can be seamlessly integrated with existing infrastructure using Cisco UCS servers, enabling customers to confidently engage in their Big Data journey.
Make sure to subscribe to our blog to get our latest updates to your inbox. The white paper covering this solution will be published shortly and we’ll share it with you here.
This blog was written by Prasad Venkatachar, Former Technical Marketing Manager, SanDisk Enterprise Storage Solutions at SanDisk

