

In my last post on Building Converged Data Platforms, I wrote about the InfiniFlash™ platform and how it provides the performance demands required for a real-time analytics tier. Since my last blog, SanDisk® joined the Western Digital family of brands alongside HGST. In this post I will look at how HGST software-defined object storage, using HGST Active Archive System, can be used to deploy an effective data lake, complementing a flash tier or as a standalone data repository.
[Tweet “The case for #objectstorage based Data Lake #hadoop #bigdata”]
The Case for Object Storage-Based Data Lake Platform
Digital transformation is forcing businesses and customers to look at Business Process Management (BPM) with fresh eyes. Business Process Discovery (BPD) and business process optimization are becoming cornerstones for verticals like:
- Financial Services Industry (FSI)
- Life Sciences and Genome processing
- Healthcare
- Media and Entertainment
- Manufacturing
Due to a data deluge, technology advances like the Internet of Things (IoT) are making this process even more complex.
Business process mining is being adopted by both existing POSIX-compliant applications, as well as new cloud native applications, to provide descriptive, predictive, and prescriptive analytics. As such, an ideal data lake platform needs to be able to provide both object interface for new applications, as well as NFS and file ingest for existing POSIX applications.
Using the HGST data lake platform object store allows data to be stored at low cost, with high durability and built-in data management and protection (versioning).
Once the process data is available, it can be effectively used for:
- Process discovery
- Process optimization
- Implementing machine learning
- Total Quality Management (TQM)
- Continuous Process Improvement (CPI)
- Six Sigma to optimize Business Process Management
The HGST Data Lake Platform – Object-Based Data Lake
The HGST data lake platform system is a highly scalable object store that can grow from 672TB (raw) up to 5.8PB per rack to help you deliver your business objectives on a “pay-as-you-grow” basis. For data that requires long-term retention with easy and fast retrieval, the system provides outstanding levels of simplicity, scalability, resiliency, and affordability
Using the S3A Data Lake Connector for Analytics
Hadoop with YARN is turning into a “Data Fabric Framework” for batch, interactive, and real-time analytics as it allows the co-existence of both HDFS and S3 (key value object store). S3A is an open source S3 connector for Hadoop, and is the successor to S3n. Unlike S3n that is based on the JetS3t library, the S3A connector is based on the Amazon Web Services (AWS) SDK, which guarantees full compatibility with the AWS S3 API and allows Hadoop users to read and write data to S3 object store directly from Hadoop
HGST has been a leading contributor to S3A and has provided several performance enhancements and bug fixes to the Apache Foundation Hadoop framework. As such the S3A connector is fully optimized to take advantage of the full performance spectrum of the HGST data lake platform, resulting in 7-10x faster write speed.
S3A introduces the following performance advantages:
- File upload and copy support for files greater than 5GB.
- Significantly faster performance, especially for large files.
- Parallel upload, copy, and rename support, which results in dramatically faster commits on large files.
- AWS S3 explorer-compatible empty directory support.
- Partial reads without having to download the whole file, which results in a major performance gain for large files.
HGST has also developed guidance for using S3A with popular data analytics distributions such as Cloudera, Hortonworks, and Spark so you can take advantage of optimal deployment scenerios.
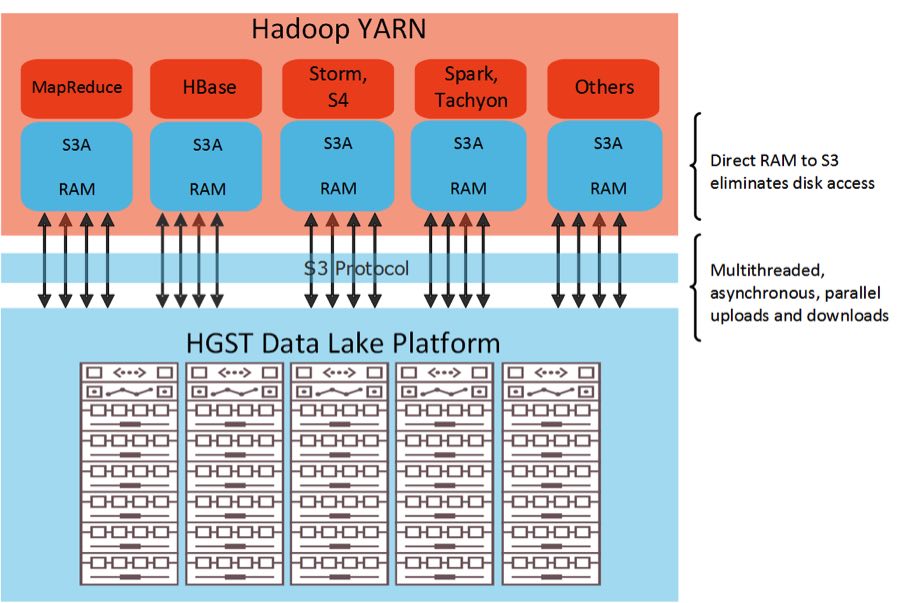
The HGST Data Lake Platform Value Proposition
Beyond leveraging the S3A protocol and advanced object storage software, the data lake platform delivers several key advantages for data lake deployment, including:
- From 672TB to over 35PB Object Storage System that lets you scale-up and scale-out as you grow.
- Advanced erasure-coded storage techniques so that Hadoop users can achieve much higher storage efficiency than HDFS, and eliminate the overhead of data movement required when using HDFS.
- Up to 15 nines of storage durability using only 1.6x storage overhead factor when compared to HDFS 3x replication.
- High I/O throughput with data lake S3 object store, including read performance of up to 3.5 GB/s per deployed rack.
- Extremely low $/TB and watts/TB that can be installed and deployed in minutes.
- HGST data lake has a rich ecosystem of ISV partners like CTera, Versity, Avere, etc. which allow existing operational datastores to ingest data using a POSIX-compliant file interface. Cloud native applications can directly use the object interface for ingest. Once in the data lake, the datastore can be analyzed using the S3A connector for the analytics framework
[Tweet “Building an #Analytics-Converged Data Platform with Object Storage #hadoop #yarn #MapReduce”]
Proof is in the Pudding: HGST On Premise vs. Public Cloud Data Lake
We decided to prototype and compare between the on-premises HGST data lake platform and an off-premises data lake hosted in the public cloud. The pilot and testing were conducted by our Advanced Technology group led by Dr. Sanhita Sarkar, Technology and Advanced Development, DCSBU, all the way from the infrastructure piece to process mining to using machine learning methodologies, to visualization. The results were eye opening!
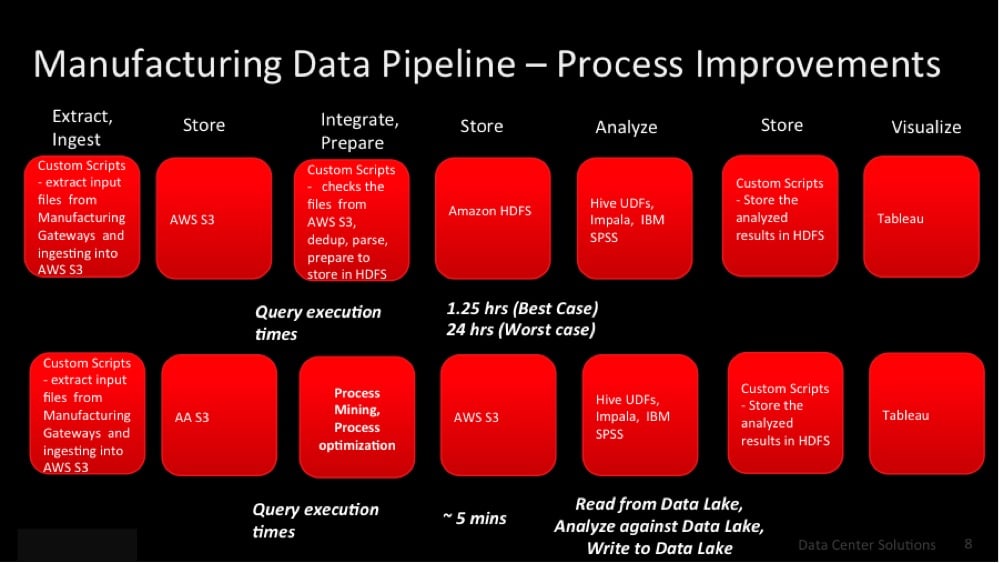
The Data Pipeline
The data pipelines for both the public cloud data lake and the on-premises deployment were as follows:
- Data was extracted using custom scripts and stored either in the public cloud data lake (off-premises) or the HGST data lake platform data lake (on-premises) for analytics.
- For the public cloud data lake, custom scripts were used to cleanse and prepare the data to be stored in the public cloud HDFS.
- In the case of on-premises, process mining and optimizations were applied to the stored process data and metadata for optimal query performance following this phase.
- In both cases the data was analyzed using Hive UDF (user defined function) queries and the IBM SPSS (IBM Statistical Analysis package) for machine learning using K-Means clustering.
- The data was then stored and visualized using Tableau.
- Compute instances were used for both cases using 40 worker nodes in the cloud and 16 worker nodes with the HGST data lake platform.
There were three different approaches tested for the HGST data lake platform on-premises data lake:
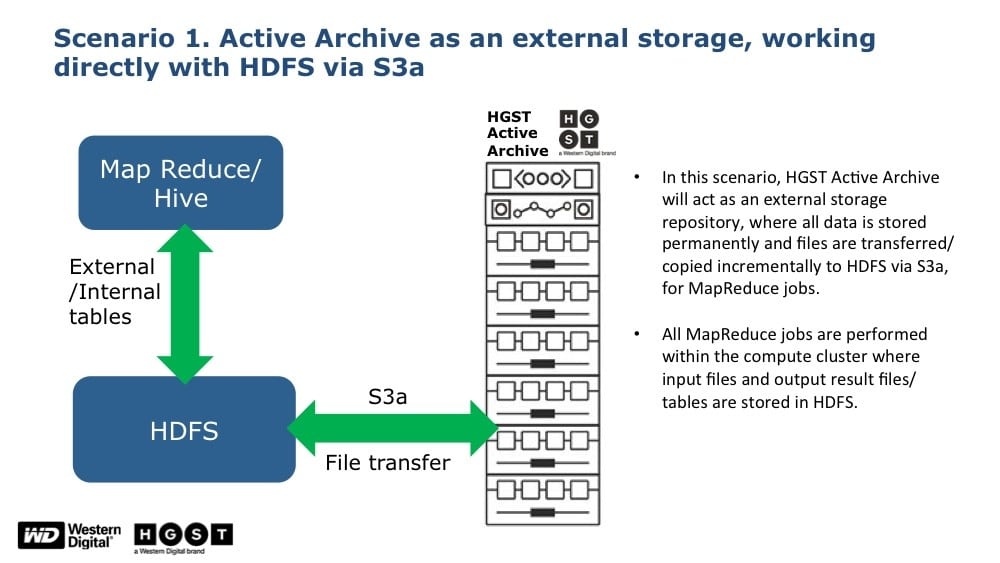
Scenario 1: HGST data lake platform was used as a landing zone, with data loaded incrementally to an HDFS layer, analyzed using MapReduce with the results stored in HDFS and eventually moved to the data lake.
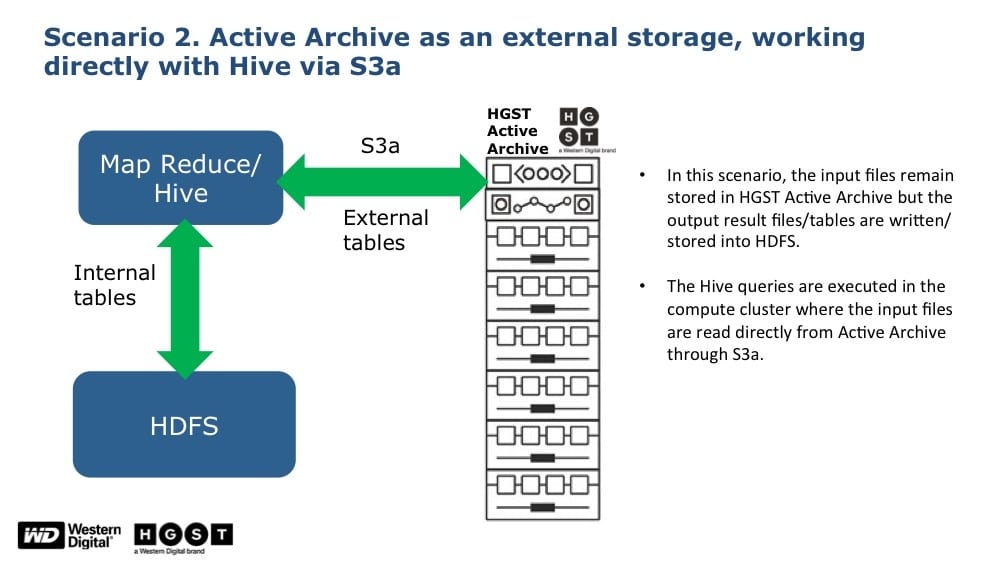
Scenario 2: HGST data lake platform was used as a landing zone and data was retained there natively. Data was read directly into the compute layer, analyzed, and written back to the HDFS layer and eventually moved to the data lake.
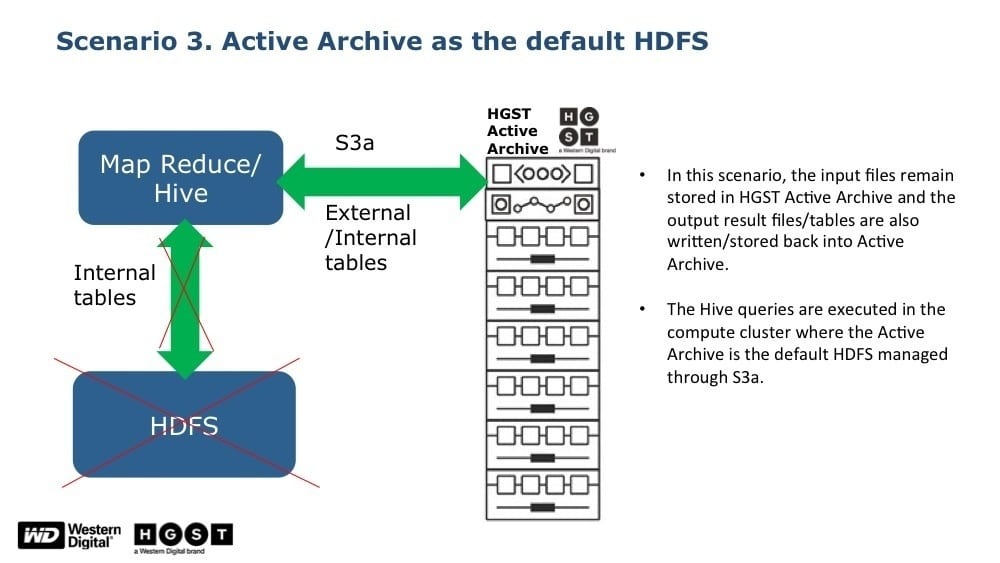
Scenario 3: Analytics are run directly in the HGST data lake, with no data movement, thus demonstrating true “in-place analytics”
In all three scenarios, the results provided a magnitude of order better when compared to a data lake hosted in the public cloud. Our benchmarks were able to demonstrate a fourth of the Total Cost of Owndership (TCO) with over 17 times better performance!
Here’s an overview of the data pipeline and performance results:
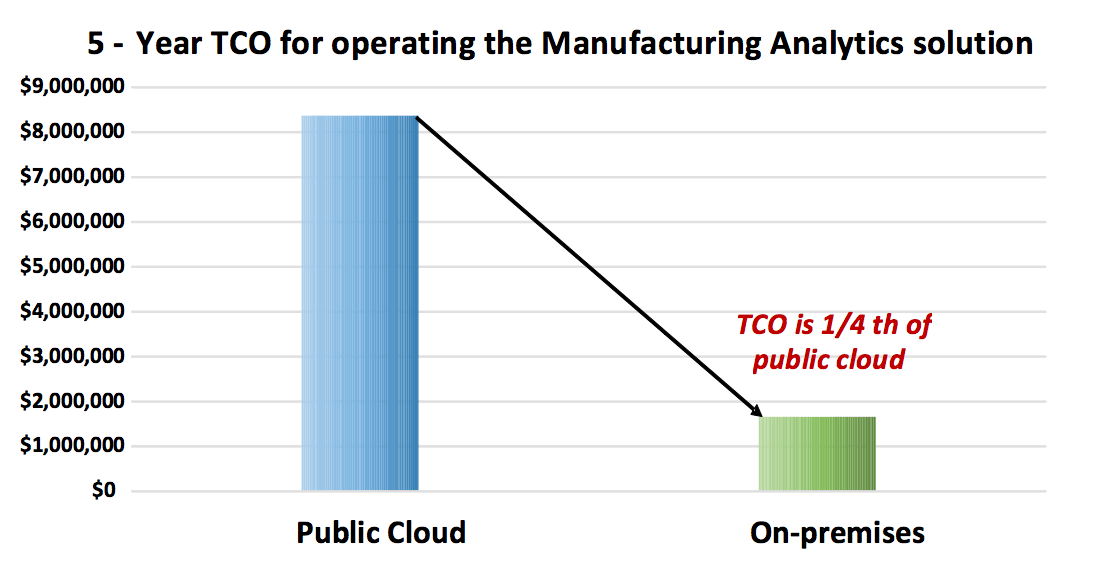
When looking at the long-term, five-year TCO calculation comparing the on-premises HGST Data Lake Platform Data Lake ownership vs. running the process data in a public cloud provider today, we also found a significant improvement of 4x! This calculation looks at the cost of hardware ownership, operational costs and software licenses in comparison to ongoing monthly charges of storage, compute and SaaS as available in leading public cloud today.
Conclusion
The HGST data lake platform breaks away from the conventional DAS model to a disaggregated infrastucture system, allowing storage and compute to scale independently, while providing the needed data locality for applications to perform optimally for a converged data platform.
The HGST Active Archive System as a data lake platform is an ideal repository for all raw data from business process events followed by actionable Business Process Management. The dynamically provisioned platform allows for flexibility in configuring multiple input data sizes of various workloads, on demand, with deployment options allowing coexistence of HDFS and S3 or a standalone S3.
This durable, extreme low cost, (multi-geo) storage for Hadoop workloads can store, analyze, and visualize vast amount of unstructured data to enable new use cases for process discovery, process mining, and process optimization that can be leveraged across industries.
–

