Guest blog post by SanDisk® Fellow, Fritz Kruger
Dear IT industry, we have a problem, and we need to take a moment to talk about it.
Until not too long ago, the world seemed to follow a clear order. The trajectory of processor speed relative to storage and networking speed followed the basics of Moore’s law. But this law and order is about to go to disarray, forcing our industry to rethink our most common data center architectures.
The Data Center Triad
Historically, storage used to be far behind Moore’s Law when HDDs hit their mechanical limitations at 15K RPM. For a long time there was an exponential gap between the advancements in CPU, memory and networking technologies and what storage could offer. In fact, server and storage vendors had to heavily invest in techniques to work around HDD bottlenecks. But with flash memory storming the data center with new speeds, we’ve seen the bottleneck move elsewhere.
In the days of spinning media, the processors in the storage head-ends that served the data up to the network were often underutilized, as the performance of the hard drives were the fundamental bottleneck. But with flash, the picture is reversed, and the raw flash IOPS require some very high processor performance to keep up. The same story applies to the network on the other side of the head-end: the available bandwidth is increasing wildly, and so the CPUs are struggling there, too. The poor processor is now getting sandwiched between these two exponential performance growth curves of flash and network bandwidth, and it is now becoming the fundamental bottleneck in storage performance.
The Worrisome 2020 Trend
The bandwidth of flash devices—such as a 2.5” SCSI, SAS or SATA SSDs, particularly those of enterprise grade—and the bandwidth of network cables—like Ethernet, InfiniBand, or Fibre Channel—have been increasing at a similar slope, doubling about every 17-18 months (faster than Moore’s Law, how about that!).
We can easily see continued doublings in storage and network bandwidth for the next decade. High performance networking will be reaching the 400 Gigabit/s soon, with the next step being the Terabit Ethernet (TbE), according to the Ethernet Alliance.
Here is where things get complicated.
In comparison to storage and network bandwidth, the DRAM throughput slope (when looking at a single big CPU socket like an Intel Xeon) is doubling only every 26-27 months. And it’s slowing down. Sure, CPUs have a lot more cores, but there’s no way to feed them for throughput-bound applications. While (flash) storage and the networking industry produce amazingly fast products that are getting faster every year, the development of processing speed and DRAM throughput is lagging behind.
Take a look below at the trajectory of network, storage and DRAM bandwidth and what the trends look like as we head towards 2020. As you can see, the slope is starting to change dramatically, right about now.
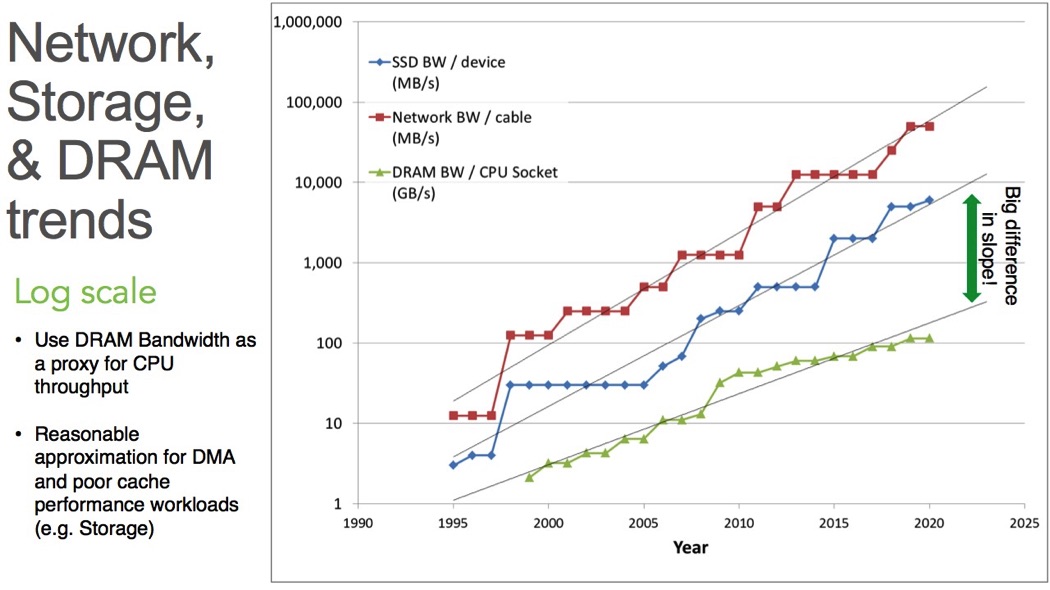
Why am I talking about DRAM and not cores? When we look at storage, we’re generally referring to DMA that doesn’t fit within cache. We’re moving bits in and out of the CPU but in fact, we’re just using the northbridge of the CPU. In that sense I’m using DRAM as a proxy for the bandwidth that goes through the CPU subsystem (in storage systems).
Towards Infinite Storage Bandwidth
I plotted the same data in a linear chart. And here you’ll see an enormous, exponential delta. We are approaching the point (if we haven’t already reached it in some instances) of massive disparity between storage and network bandwidth ratio.
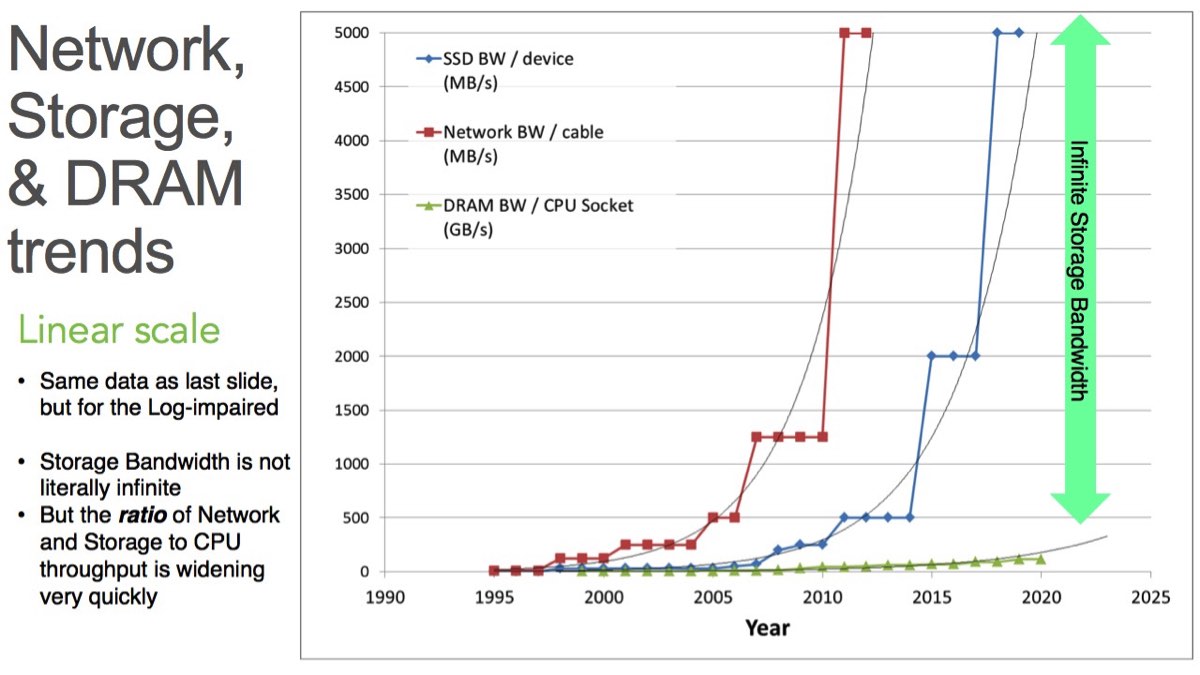
Ok, so storage bandwidth isn’t literally infinite… but this is just how fast, and dramatic, the ratio of either SSD bandwidth or network bandwidth to CPU throughput is becoming just a few years from now. It’s untenable.
What does this mean for data center architecture?
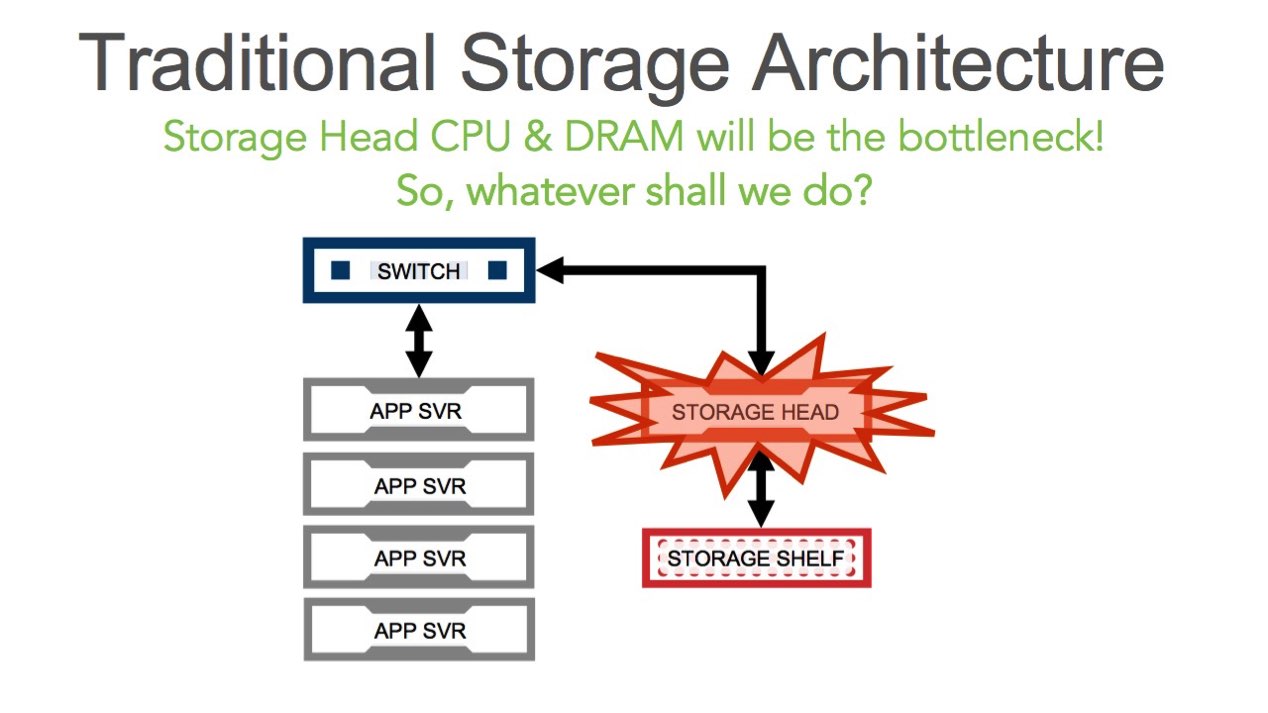
The traditional SAN and NAS paradigm is architected using multiple application nodes, connected to a switch and a head node that sits between the application and the storage shelf (where the actual disks reside). This head node is where the CPU is located and is responsible for the computation of storage management – everything from the network, to virtualizing the LUN, thin/thick provisioning, RAID and redundancy, compression and dedupe, error handling, failover, logging and reporting.
Looking forward, fast network and storage bandwidths will outpace DRAM & CPU bandwidth in the storage head. The pipe from the applications going in will have have more bandwidth than what the CPU can handle and so will the storage shelf. In fact, we can already feel this disparity today for HPC, Big Data and some mission-critical applications. And in less than 5 years this bandwidth ratio will be almost unbridgeable if nothing groundbreaking happens.
Getting the CPU Out of the Datapath
No matter how we look at it, the standard CPU platform is becoming the bottleneck.
So what do we do?
The industry needs to come together as a whole to deliver new architectures for the data center to support the forthcoming physical network and storage topologies.
I welcome your comments, feedback and ideas below!
The data in the graphs was created for informational purposes only and may contain errors. It also contains information from third parties, which reflect their projections as of the date of issuance.