
In my first blog post on the SanDisk® ITBlog, I talked about testing the Terasort benchmark using SanDisk CloudSpeed SSDs within an Apache Hadoop data-analytics environment. The blog and the more detailed technical paper that followed talked about the significant performance and TCO benefits that can be achieved by strategically using SSDs within a Big-Data Hadoop infrastructure.
Continuing SanDisk’s research on SSDs in a Hadoop infrastructure, our team tested another Hadoop benchmark, TestDFSIO. TestDFSIO is a storage-intensive benchmark which allows testing Hadoop workloads with 100% read operations or 100% write operations. It requires, as input, the number of files to be read/written along with the file size and the type of operations (read/write). For the 100% write workload, the files are written to HDFS. For the 100% read workload, files which already exist on HDFS are read. Tpically, TestDFSIO benchmark testing is conducted by first doing the 100% write workload, followed by the 100% read workload, which then allows reading the files that were written by the write operation.
Flash-Enabled Hadoop Cluster Testing
Our team tested the TestDFSIO benchmark on the same Hadoop cluster which was used for the Terasort testing. The cluster was installed with the Cloudera® Distribution of Hadoop (CDH) on Red Hat® Enterprise Linux. This cluster consisted of one NameNode and six DataNodes, which was set up for the purpose of determining the benefits of using SSDs within a Hadoop environment, focusing on the Terasort benchmark.
We ran the Hadoop TestDFSIO benchmark on two different cluster configurations:
- All-HDD configuration: The Hadoop DataNodes use HDDs for the Hadoop Distributed File System (HDFS), as well as Hadoop MapReduce.
- All-SSD configuration: In this configuration, the HDDs of the first configuration are swapped with SanDisk SSDs. So, both the DataNodes and MapReduce tasks use SSDs.
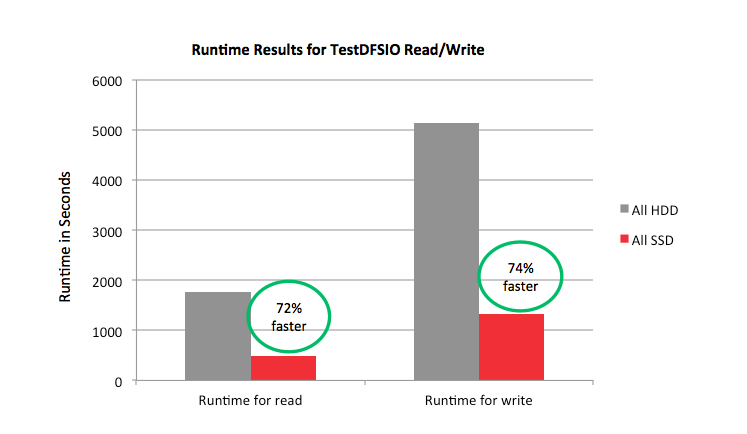
For each of the above configurations, TestDFSIO runs were conducted for read and write operations, using 512 files, each with 2000 MB of data. The file size and the number of files used resulted in a 1 TB dataset. The runtime and throughput results were captured for the various TestDFSIO runs.
Results – Runtime Performance
The total runtime results for the TestDFSIO benchmark are shown in the graphs below, quantifying the improvements seen with the SSD configurations. SSDs helped improve the runtime for the read and write TestDFSIO runs by more than 70%.

Cost per Job Analysis
The runtime improvements shown above indicate that switching over to SSDs for big-data analytics tasks on Hadoop can help reduce time-to-results for organizations. But to take advantage of SSDs, most organizations will have to consider the initial investment that comes with purchasing SSDs. However, one should consider the cost spread over the lifetime of the SSDs (not only the purchasing investment) and the benefits achieved to the overall big-data infrastructure. This cost can better be evaluated by looking at the cost/job.
The runtime results for the various TestDFSIO runs were used to determine the total number of jobs that can be completed on the Hadoop cluster over a single day. This number was then extrapolated over a hypothetical lifetime of the cluster, which was chosen as 3 years. The total cost of the Hadoop cluster was then used with the total number of jobs over 3 years to determine the cost per job metric for the Hadoop cluster.
These calculations helped us compare the cost/job of the All-HDD and All-SSD Hadoop cluster configurations, as can be seen in the chart below:
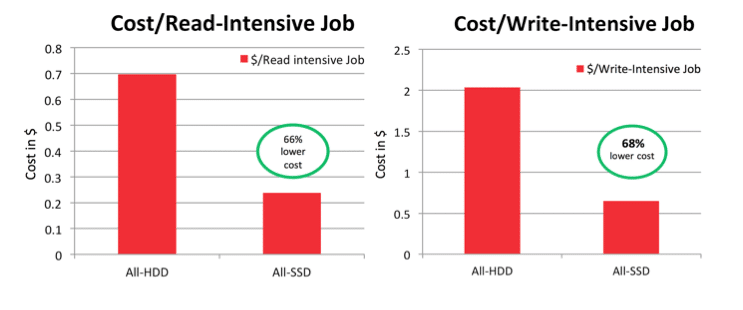
The cost/job results show that SanDisk’s all-SSD configuration can reduce the cost/job by more than 60% when compared to the all-HDD configuration for both read-intensive and write-intensive workloads. Effectively, this can drive the total cost of ownership (TCO) lower for the SanDisk all-SSD Hadoop configuration in comparison to an all-HDD configuration.
You can learn more about the Apache Hadoop TestDFSIO benchmark test we performed with SanDisk SSDs and our results by downloading the detailed technical paper ‘SanDisk® CloudSpeed™ SATA SSDs Support Faster Hadoop Performance and TCO Savings’ from the SanDisk.com website. You can reach out to me at madhura.limaye@sandiskoneblog.wpengine.com if you have any questions, and join the conversation with us on flash and big data on Twitter at @SanDiskDataCtr.

