

In today’s hyper-connected world, there is a significant amount of data being collected, and later analyzed to make business decisions. This explosion of data has led to various technologies that can operate on this “Big-Data”, technologies for Big-Data Analytics. Traditional database systems and data warehouses are being augmented with newer scale-out open-source technologies like Apache Hadoop and NoSQL databases like Apache HBase, Cassandra and MongoDB to manage the massive scale of data and its analysis.
To explore the benefits of SanDisk® Solid State Drives (SSDs) in this new world of data warehousing and analytics, SanDisk completed a set of tests using CloudSpeed Ascend SSDs in an Apache HBase deployment. The Yahoo! Cloud Serving Benchmark (YCSB) was used to gather data related to transactions/second and read and write operations latencies for this ‘Apache HBase + SanDisk SSD’ environment.
Apache HBase
Apache HBase is an open-source, distributed, scalable, big-data database. It is a non-relational (also called NoSQL) database, unlike many of the traditional database systems. Apache HBase uses the Hadoop Distributed File System (HDFS) in distributed mode. HBase can also be deployed in standalone mode, and in this case it uses the local file system. It is used for random, realtime read/write access to large quantities of data. Apache HBase uses Log Structured Merge trees (LSM trees) to store and query the data. It features compression, in-memory caching, and very fast scans. HBase tables can serve as both the input and output for MapReduce jobs.
Here are some features of HBase:
- Linear and modular scalability
- Strictly consistent reads and writes
- Automatic and configurable sharding of tables
- Fault tolerant and highly available via automatic failover support between RegionServers
- Convenient base classes for backing Hadoop MapReduce jobs with Apache HBase tables
- Easy to use Java API for client access, and Thrift or REST gateway APIs
- Near Real-time query support
- Support for exporting metrics via the Hadoop metrics subsystem to files or Ganglia; or via JMX
YCSB benchmark
Yahoo! Cloud Serving Benchmark consists of two components:
- The client, which generates the load according to a workload type and records the latency and throughput.
- The workload files, which define the workload type by describing the size of the data set, the total number of requests, the ratio of read and write queries.
There are 6 major workload types in YCSB (Worloads A-F). Each of these workloads can choose one of two types of workload distributions, uniform or zipfian.
Out of the available YCSB workload types, SanDisk conducted testing for the update-heavy workload (Workload A) and 2 read-heavy workloads (Workload B & C) using:
1. Two storage configurations
a. All-HDD configuration
b. All-Flash or All-SSD configuration
2. Two different dataset sizes
a. 64 GB
b. 256 GB
3. And two different workload distributions
a. Uniform
b. Zipfian
This blog summarizes the results of a few of these experiments. The detailed test methodology and the results analysis will be shared via a soon to be published technical paper.
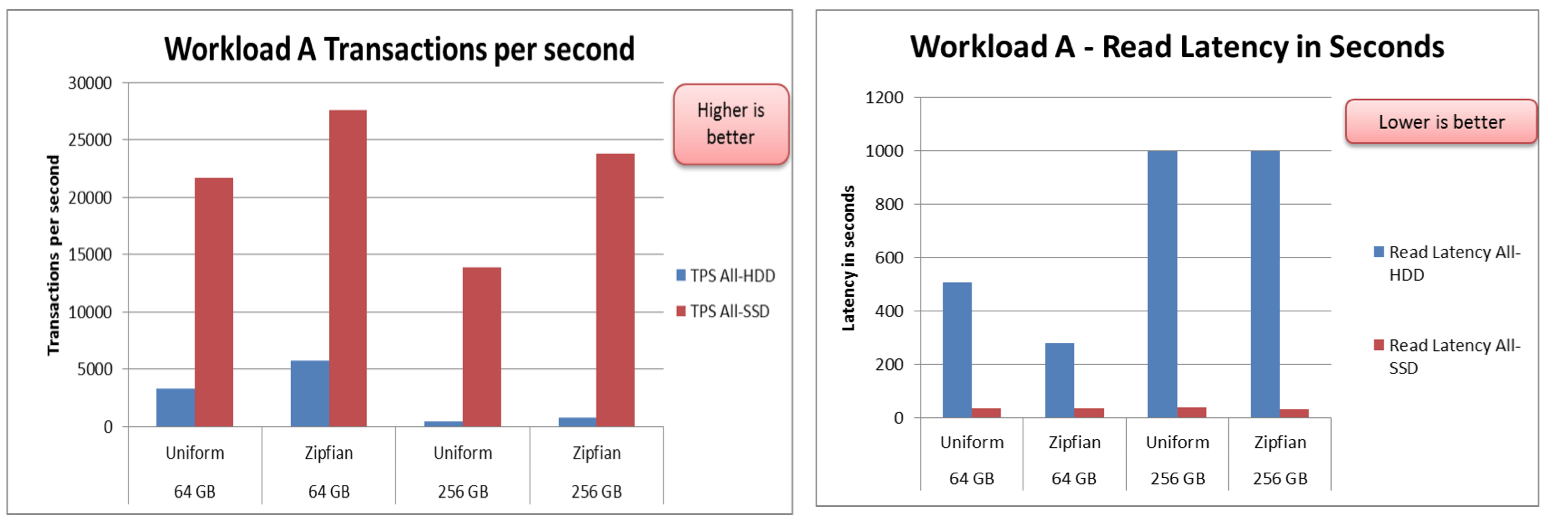
Update intensive workload results
The following graphs show the transactions/second and latency results for the different storage configurations, using different dataset sizes and distributions. The results are for YCSB Workload A which is an update intensive workload.
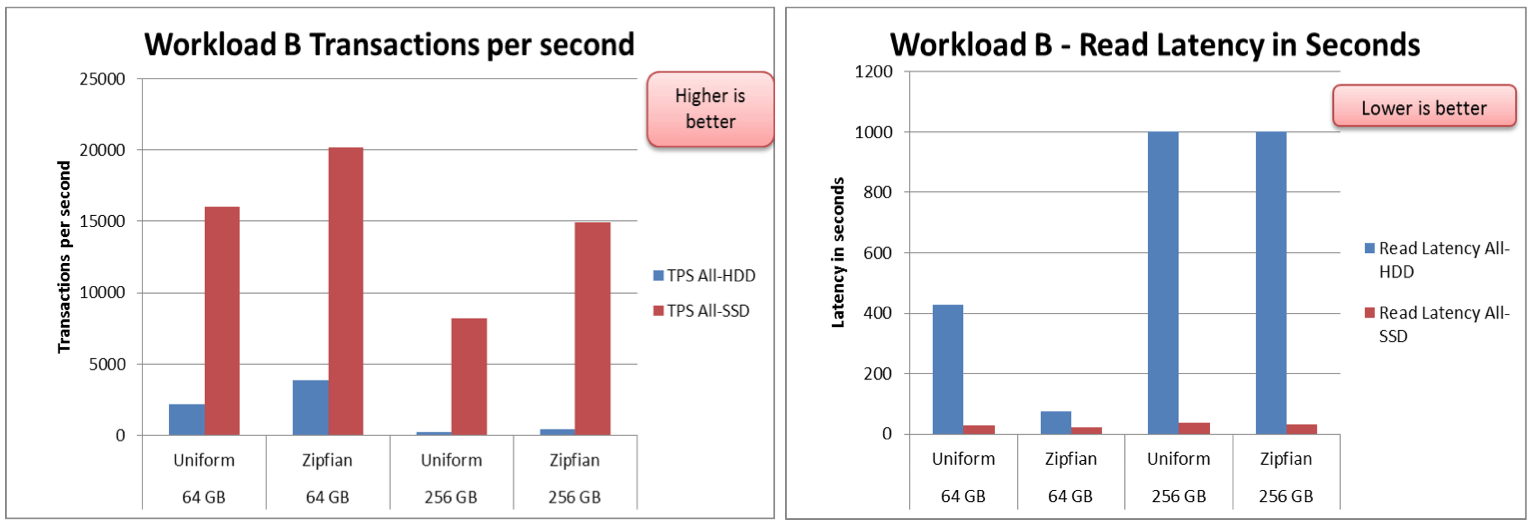
Read intensive workload results
The following graphs show the transactions/second and latency results for the different storage configurations, using different dataset sizes and distributions. The results are for YCSB Workload B which is a read intensive workload.
Conclusions
The results shown above, as well as results from additional YCSB workloads, consistently show higher transactions/second and lower latencies when using Flash Accelerated Apache HBase.
- SanDisk SSDs showed 30-40x increase in the transactions/second results when compared to traditional HDDs. These improvements were seen across the update-intensive and read-intensive/read-only workloads.
- SanDisk SSDs also consistently provided lower read latencies of less than 50 seconds, as compared to the > 1000 seconds latencies seen on HDDs.
The higher transactions per second and lower latency results seen with CloudSpeed SATA SSDs directly translate to faster query processing, thus reducing the time-to-results. In an organization’s IT department, this results in significant improvements in business process efficiency and cost-savings.
![HBASE-Apache-SSDs[1]](/wp-content/uploads/2014/11/HBASE-Apache-SSDs1.jpg)
These results justify using flash when deploying Apache HBase for business’ data analytics requirements. The performance improvements provide a compelling data point that IT managers can take advantage of, to deploy Apache HBase using SanDisk flash solutions in their IT environments.
You can reach out to me at madhura.limaye@sandiskoneblog.wpengine.com if you have any questions about these results, and join the conversation with us on flash and Big Data on Twitter at @SanDiskDataCtr.

