

In-Memory Computing – Why now?
In-memory computing has been around for decades. So, why all the attention to this computing segment the last few years?
The rise of the Digital Economy has made data the new currency of global exchange. We see how the computing power that fuels the digital economy has found its way to serve other types of vast data sets, Fast Data and Big Data, that need to be processed in real time. However the demands of safe city initiatives, IoT workloads, and other time-sensitive data sets are hitting memory constraints at scale. New architectures and solutions are critical to bring the power of compute to massive data sets.
These new architectures are memory-centric to address the pursuit of greater data processing at lower latency.
In-Memory Computing at Scale – The Next Computing Frontier
IT department adoption of In-Memory Computing (IMC) is on the rise, alongside specific use case of In-Memory technology, and stream analytics.
No doubt, In-memory computing is the latest paradigm for performance computing, but scaling memory-centric architectures and mega platforms is becoming a huge problem for SaaS, cloud providers, and enterprises that need to harness massive datasets.
Reaching the Limits of Traditional Scaling
Cloud and IT architects have adopted in-memory computing, running data sets in DRAM instead of traditional storage media (SSDs or HDDs), to achieve new data processing paradigms demanded by stakeholders of the digital economy and Fast/Big Data initiatives.
Architecting DRAM-based computing clusters should be a straightforward exercise: Have enough DRAM pool capacity across your clusters to enable your data sets to fit. Except real-time data can easily grow and exceed the limits of physical DRAM pools.
Scaling in-memory compute infrastructure is a real problem in the era of up-to-the-second decision making for larger and larger data sets.
When data sets do exceed physical DRAM pools, application performance suffers. Data swapping/paging to a lower performance tier inhibits performance in an era where the competition may have larger DRAM pools and better performance than you. Further architectural complications are encountered when software sharding across numerous nodes and LIFO data cache purging techniques put unique stresses on scaling in-memory computing.
As data sets grow, scaling In-Memory computing infrastructure has its barriers:
- Cost of DIMM modules – It’s extremely costly (see the historical rise of DDDR modules tracked on dramexchange.com).
- Large Capacity DIMM pricing doesn’t scale linearly – relative to 64GB DIMM, pricing for 128GB is not linear; a price premium is commanded for the 128GB DIMM density
- Limited DIMM slots available within servers – effective scaling may require more nodes than you anticipated because of the limited amount of available DIMM slots.
- Low CPU utilization – scaling may cause individual nodes within a compute cluster to be filled with DIMMs, but CPU utilization can’t be optimized for application loads.
Cloud and IT architects face a Sisyphean-like task to keep scaling compute clusters to accommodate growth. Just as you may scale your in-memory compute clusters, data sets will grow and exceed DRAM pools or you may realize immense CAPEX and OPEX in order to scale.
But what if you could scale memory configurations without depending just on DRAM?
New Possibilities for In-Memory Scaling
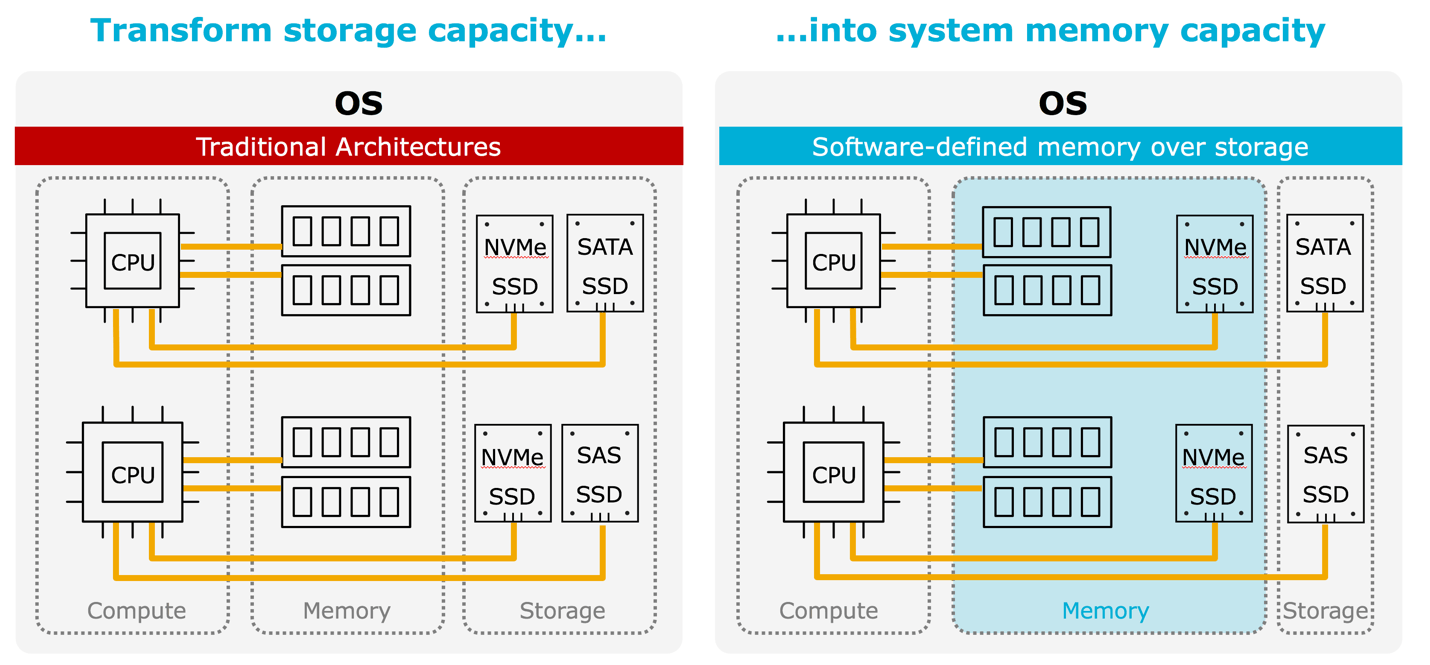
Today, Western Digital announced the extension of our portfolio into the rapidly evolving in-memory computing market with the Ultrastar® DC ME200 Memory Extension Drive.

This “memory drive” leverages Western Digital data infrastructure leadership and NVMe™ technology to augment physical DRAM, by creating “virtual memory” pools up to 8X the physical DRAM capacity. Up to 24TiB can be deployed in a 1U server with the U.2 form factor.
As a “drop-in” ready and PCIe-compatible device (NVMe U.2 or AIC HH-HL form factors), Ultrastar memory drive transforms NVMe storage capacity into system memory with near-DRAM performance. Cloud and IT architects can scale memory footprints and expand faster data processing across many applications and workloads at far lower costs than traditional DRAM-based clusters.
Using Machine Learning to Reach Near-DRAM Speed
Near-DRAM performance is achieved through the use of 20+ types of algorithms to predict, prefetch, and optimize memory and locality, as opposed to the typical single algorithm that is typically implemented in hardware (e.g., adjacent cacheline prefetch). It uses machine learning, pattern recognition, code scanning, and other techniques, which allows the Ultrastar DC ME200 to massively prefetch addresses that the CPU will be using thousands of cycles ahead, so by the time the CPU needs those addresses, they already are waiting in DRAM.
For the user, no changes to existing application stacks are necessary and broad Linux® distributions are supported.
(I’ll be sharing more about this, BIOS and Operating System Aware Memory and other technical details in my next blog.)
Scaling In-Memory Computing – A Call to Action
Sisyphus was condemned to eternity of rolling a boulder towards the top of the hill then for it to roll back down. But you can now break free of your pursuits of DRAM constraints.

Once you realize DRAM constraints can be solved today, which type of applications can you build when DRAM pools can economically be scaled to the tens of TiBs? What new workloads can take advantage of in-memory computing?
The potential of building large-scale platforms with Ultrastar memory drives can have direct impacts to genome research, natural disaster detection, safe city initiatives, the promises of IoT, and cloud computing for enterprises and personal entertainment.
Ultrastar DC ME200 Memory Extension Drive is ideal for:
- Redis™
- Memcached
- In-Memory databases
- Data Warehousing
- IoT Platforms
- Stream Analytics
- Apache Spark™, Apache Storm™, Apache Kafka®
- In-Memory Data Grids
- Application Caching
- Content Distribution (CDN)
- Containers and their data sources
- SaaS, Analytics-as-a-Service
- AI/ML
- High-Volume Logging
Learn More
Visit our website to learn more about Ultrastar memory drive. I’ll be following up with a deep technical dive and demo in my next blog. Make sure to subscribe below.

