As a reader of this blog, you know that different workloads need different storage – a high-performance transactional system like a stock-trading platform needs a different storage solution than an archival backup system.
Software-defined storage solutions like Microsoft’s Storage Spaces Direct, deliver innovative technology to pool and manage storage devices directly connected to servers. Though that alone might have seemed like magic a few years ago, it doesn’t include enough magic to overcome matching a workload to the wrong storage configuration. You wouldn’t expect a go-kart engine to power your race car, and storage is no different.
In this blog series I will be sharing some helpful, broad guidelines to optimize your Storage Spaces Direct configuration based on our workload testing. I will be sharing early results and recommendations based on various configurations running different types of workloads.
This first blog is an introduction to workloads and I/O patterns.
Storage Spaces Direct, Meet Workloads and I/O Patterns
Consider two common database workloads, data analytics and transactional processing. Data analytics, as well business intelligence and data warehouse, are read-intensive and perform large block I/O.
Table 1 reports the read I/O from a SQL Server Data Warehouse Fast Track validation test, which is similar to the TPC-H benchmark. 25.03% of reads were 1,024 KB, 7.69% were 968 KB, 3.30% were 960 KB, etc. Data analytics issues lots of big-block reads.
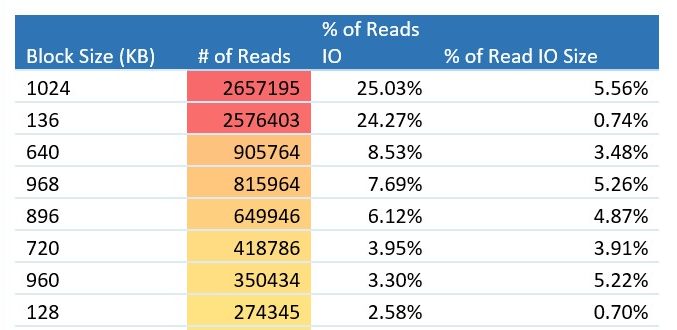
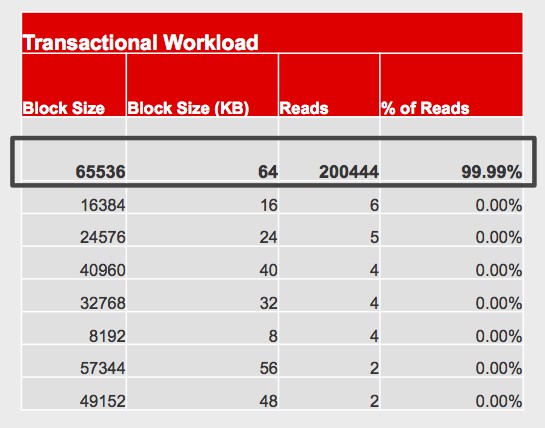
Table 2 reports the read I/O from SQL Server during Hybrid Transactional/Analytical Processing (HTAP), where transactional processing dominates the occasional analytics query. As you browse through the product catalog in an online store, 99.99% of reads are 64KB; not shown are the writes issued when you place an order, but those are 64KB or less as well. Transactional systems issue lots of small-block reads (and writes).
Hyperconverged Infrastructure, meet the I/O Blender Effect
Hyperconverged infrastructure (HCI) is often associated with software-defined storage: the server running applications – typically virtualized applications – is also providing the software-defined storage. We previously demonstrated that as you add virtualized applications to the server, the server quickly hits a storage performance bottleneck that effectively limits the number of workloads that server can support – workload density.
This is caused by the I/O Blender Effect. Consider the data analytics workload above, which issues many large-block reads. Virtualize that workload, and several more like it, and run those on an HCI server. Although each workload issues sequential reads, those reads are intermingled with the reads from all the other virtualized workloads. At the hypervisor and storage level, all that I/O gets mixed up – as if it were run through a blender. The storage system gets random I/O, even though it started off as sequential I/O.
If you also move some transactional workloads with their small-block reads and writes to that same server, that will magnify the I/O Blender Effect: the storage system gets intermingled small-block writes with large-block reads. That’s stressful both for hard disk drives (HDDs) due to increased read/write head movement, and for solid state drives (SSDs) due to the added complexity being handled by the SSD firmware. In both cases, “stressful” workloads cause increased latency, slowing I/O request completion, slowing down applications and challenging your service level agreements (SLAs).
Optimize Your Storage Spaces Direct Configuration By Matching it to Your Workload
Storage Spaces Direct supports a variety of storage configurations, combining SSDs and HDDs to meet your workloads’ storage performance needs, as shown in Table 3.
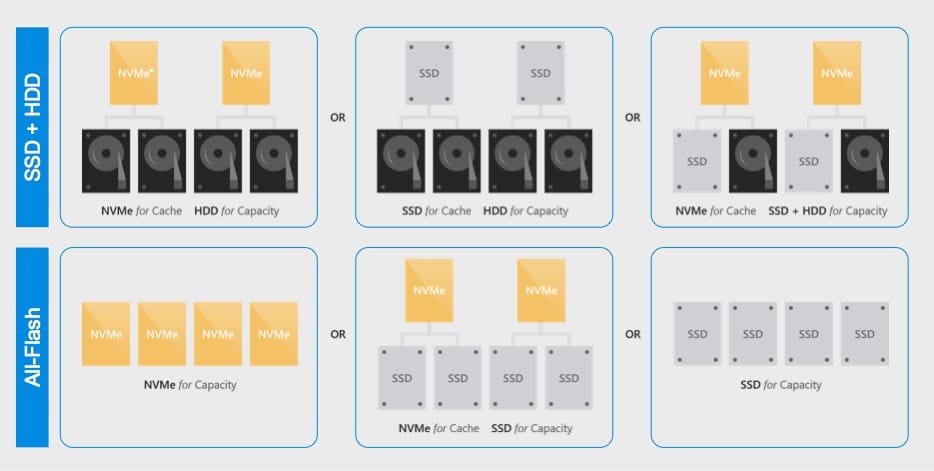
If you need blazing performance, you can use NVMe™ drives with SAS or SATA SSDs. If you need high capacity at low cost, you can use a few SSDs with many HDDs. For something in the middle, you can choose from several additional configurations.
That’s Great, But Which Should You Choose, And Why?
That’s a great question, with a complex answer – because every workload is different, so the perfect matching storage configuration will be unique. But that’s not a very helpful answer 🙂
There are actually more combinations than Table 3 indicates. To start with, HDDs and SSDs are available as both SAS and SATA. As well, Western Digital’s product portfolio includes multiple HDD product families that are helium- or air-filled at different capacities and price points, and multiple SAS SSD product families with different endurance (DW/D) and price points.
Too much complexity! Too many permutations! How do I choose?!
Western Digital’s Data Propulsion Labs™ team is testing many different Storage Spaces Direct configurations, and based on some early results we can get you started with some broad guidance on how to best power your enterprise applications and Big Data and Fast Data initiatives. We’ll continue provide additional guidance as additional testing is completed and new products in our portfolio are released.
In my next blog, I will share our first testing results and some initial guidance for different type of workloads.