

There is an immense amount of effort put into digitizing our world. More and more objects are given digital identities, connected to one another, made searchable, enable new patterns, or explored for possible new insights. At the heart of this is machine learning, and its adoption across all industries is growing at an incredible rate. The numbers speak for themselves: patents related to machine learning were in the top three among all patent categories in the last few years [1], spending is expected to jump 5x and approach nearly $60B by 2021, and implementations to grow 4x from 2017 to 2020 [2].
The success and promises of machine learning also mean we’ll see an increased dependency on it in the future. The type of workloads, and their scale, will be increasing and taking on new applications and use cases. With algorithms and software becoming more sophisticated, we’re enabling machines to learn and adjust through a complex web of neural networks on their own. Therefore, we need to find better data infrastructure schematics to drive machine learning efficiently at-scale.
Machine Learning Today – Compute Intensive Workflows
Machine learning workflows today are highly compute-intensive. Digitized objects use different data storage models and many different frameworks to feed data to a complex web of neural networks. There, data sets undergo many different combinations of mathematical transformations and solve multi-dimensional systems of equations (linear or non-linear) to discover patterns and connections among each other. Once identified, the complex web of neural network is then trained and validated to analyze and detect patterns that can predict outcomes on real-time data streams. This could be computer vision, detection such as in surveillance, and real-time actions for autonomous car applications.
Machine learning relies on a massive amount of multiplications and additions between a multitude of data and parameters. It’s extremely complex for systems with ultra large inputs. These workloads are moving beyond just CPU and take advantage of GPUs, TPUs or FPGA-based custom data path accelerators. That’s because these workloads, or mathematical operations for data transformation, require rigorous and large queue depth processing engines. In CPU memory, every single calculation result to be stored in the CPU. The Arithmetic Logic Units (ALU), what holds and controls the multipliers and adders, executes them one by one. The complexity of machine learning needs optimized approaches to processing, the instruction set pipeline, thread controls, caches, memory, and storage architectures.
Current GPU Architecture for Machine Learning
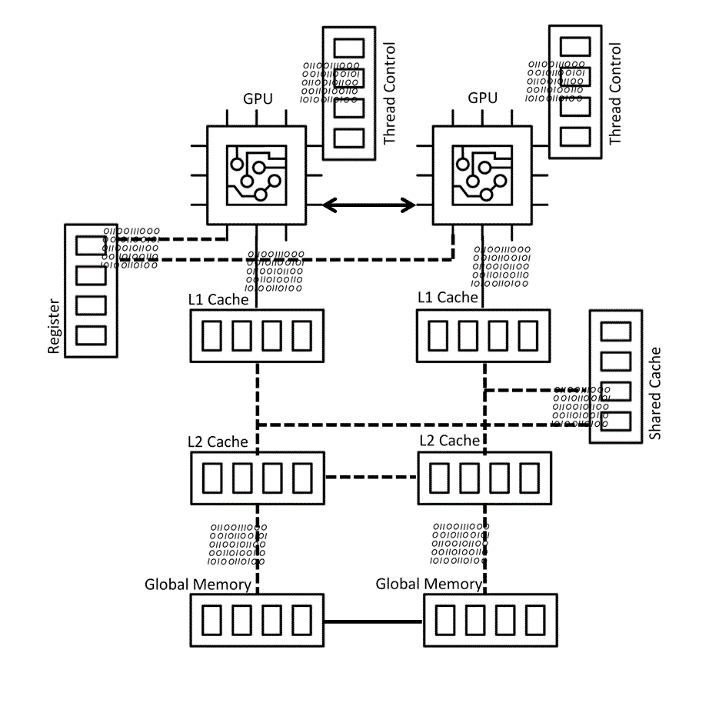
The most common choice for machine learning processing today are GPU units. GPUs are particularly popular among machine learning workloads because of higher ALU and register counts. These can support multi-threaded and higher queue depth in compute intensive applications such as distributed databases, search analytics, and pattern identification related models.
The GPU compute architecture has dedicated and shared caches, shared memories with higher bandwidth to serve large number of ALUs, and ability to process out of turn requests in a multithreaded workload environment. Modules generally open and close millions of files in parallel, and read them concurrently. The whole workflow is accelerated by data flowing through data path accelerators and latencies are reduced with the help of memories and caches (See Figure#1).
A Future of Intelligent Edge and Machine Learning at Scale
As we move forward, more and more always on, IoT devices will constantly ingest and even process some data at the intelligent edge. Machine learning data management, as well as model building, validation, and updating processes, will become a real-time operation. We’ll see applications having dynamic and constantly adjusting inputs, rich with contextual metadata. The entire machine-learning model will have to be functionally ready to deliver almost instantly at a greater scale than ever.
Furthermore, we’ll see edge compute processing some data on board and sending remaining data to a centralized system in order to build more intelligent machine learning models and gain further insight. Imagine thousands of autonomous vehicles continuously feeding streams of data sets to various machines running dedicated algorithms at the edge or at cloud arrays. Or security surveillance systems storing billions of frames every day across multiple cities and using custom hardware to design and train the machine learning models for a gamut of applications. Similarly, weather prediction as well as healthcare systems will require huge memory and tiers to feed the compute hungry GPU systems, and massive storage to push that data to. This emphasizes the importance of custom hardware and workload acceleration subsystem for data transformation and machine learning at scale.
Machine Learning Scaling Challenges
Today’s common machine learning architecture, as shown in Figure#1, is not elastic and efficient at scale. It offers limited scaling choices. For example, the system does not allow flexibility to mix and match, or increase and decrease cache and memory attach with processing units. If more memory/caches are needed for a specific GPU/ TPU to support bigger and complex data analysis, users need to buy more compute as well (see Figure #2). Some companies are solving this by designing a new compute sub system, which can serve the compute and memory needs of specific workloads. This is a complex option that requires a lot of in-house knowledge and is high-cost.
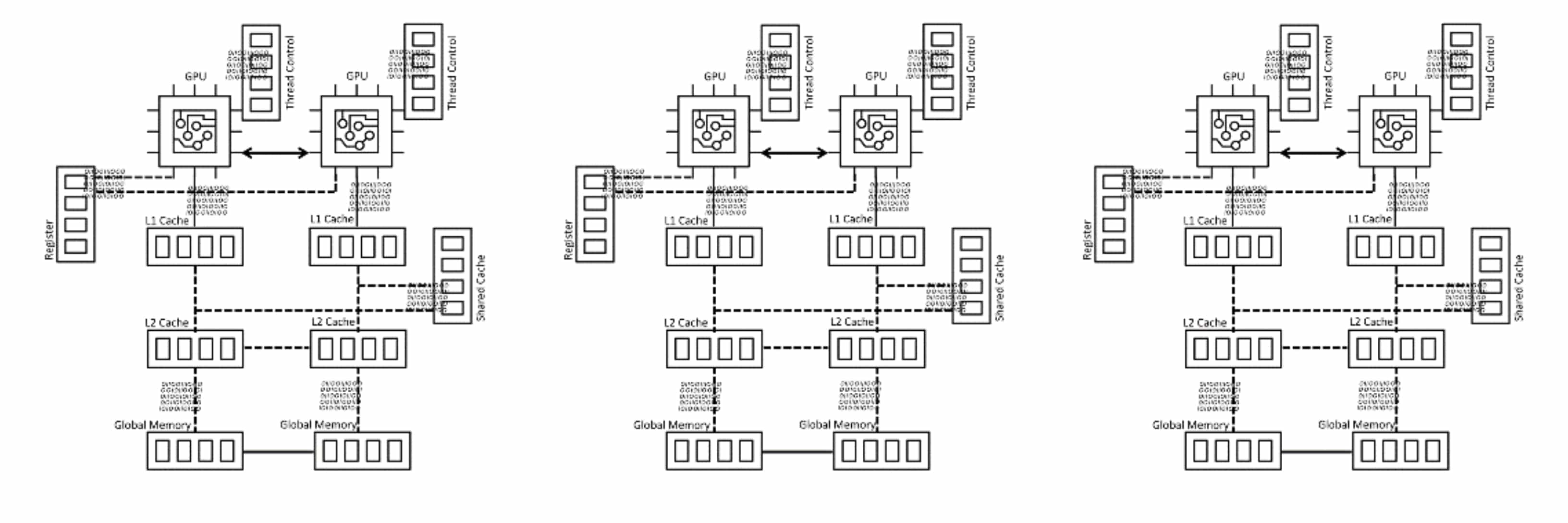
It’s inevitable that we will need to find ways to scale machine learning better. With more digitization and implementation increasing across different industries, the data size and the complexity of machine learning models will increase as the algorithms evolve. Memory scaling and resiliency would require compute scaling as well to offer a more efficient and flexible fit for scale out architectures.
New Architectures for Machine Learning at Scale
Now how do we solve this vertical scaling (or scale up) challenge? For the wider adoption of machine learning, beyond hyperscale and web-scale companies, we need to focus on infrastructure reuse and vertical scaling of the existing hardware systems.
One such example architecture, as appears in figure #3, takes on a three-tier approach:
- Processing tier – memory and caches
- Intermediate tier – accelerated by NVMe™
- Cold storage tier – hybrid storage, object storage, JBOD or cloud
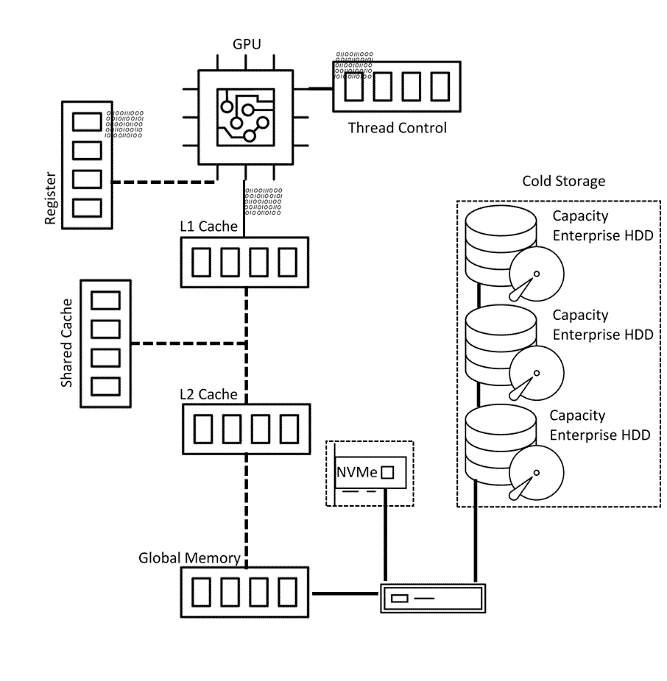
The idea is to support a compute and memory tier with the bulk of data stored in large capacity enterprise HDDs either on premises or using public cloud infrastructure (both options support a multi/ hybrid cloud strategy for end users) and employing the power of NVMe to accelerate data in the intermediate tier.
NVMe is much more than fast flash. It is a completely different protocol for accessing high-speed storage media, and can support multiple I/O queues – up to 64K with each queue having 64K commands. This is in comparison to legacy SAS and SATA that can only support single queues with 254 & 32 entries respectively. This allows NVMe to have incredible bandwidth with ultra-low latency (here are some great examples).
The other benefit of NVMe being so fast that is that we can use it to augment system memory, with performance levels at near DRAM speeds, and at far lower costs than DRAM. See the Ultrastar® DC ME200 Memory Extension Drive to learn more about this new technology. This can be very helpful for machine learning modes useful for in-memory workloads.
With this architecture, the machine learning data management modules can now open and read multiple files and transfer data from HDD/ Hybrid systems or public cloud to high speed NVMe storage or Memory Extension drives, as an intermediate tier, and then transfer data to memories and caches in batches. This creates a perfect data pipeline where not everything goes to memory and caches unless needed.
Machine Learning Will Need to Be Cost-Effective to Scale
When thinking of how to scale such workloads, we focused on cost-effective infrastructure. With only the required data being brought into the memory tiers, the remaining data can stay in low cost storage tiers, such as Western Digital ActiveScaleTM object storage system, extreme capacity and high-density enclosures such as the Ultrastar Data60, Ultrastar Data102 or in public cloud infrastructure. The high performance NVMe subsystem adds not only performance, but allows for infrastructure reuse and the effective utilization of existing systems and hardware.
As a whole, the proposed architectures also offers both scale up and scale out architecture support. This can help more organizations adopt machine learning and help machine learning workloads to scale and evolve to meet next generation application needs.
Learn More
- Get to know our data center NVMe SSD solutions
References
[1] Fast Growing Technologies of 2019
Forward-Looking Statements
Certain blog and other posts on this website may contain forward-looking statements, including statements relating to expectations for our product portfolio, the market for our products, product development efforts, and the capacities, capabilities and applications of our products. These forward-looking statements are subject to risks and uncertainties that could cause actual results to differ materially from those expressed in the forward-looking statements, including development challenges or delays, supply chain and logistics issues, changes in markets, demand, global economic conditions and other risks and uncertainties listed in Western Digital Corporation’s most recent quarterly and annual reports filed with the Securities and Exchange Commission, to which your attention is directed. Readers are cautioned not to place undue reliance on these forward-looking statements and we undertake no obligation to update these forward-looking statements to reflect subsequent events or circumstances.

