

By Jorge Campello De Souza
Earlier this week, we announced the Zoned Storage Initiative, an initiative focused on data infrastructure, and more specifically on open data infrastructure designed to take advantage of Zoned Storage Devices (ZSDs).
Zoned Storage is a new paradigm in storage motivated by the incredible explosion of data. Our data-driven society is increasingly dependent on data for every-day life and extreme scale data management is becoming a necessity. Already today, large scale data infrastructures utilize tens of thousands of HDDs and SSDs. Hyperscale companies need to be able to carefully manage them from a global perspective in a cost-effective way. Zoned Block Device technologies were introduced with the goal of moving us towards efficient data management in large-scale infrastructure deployments.
In this blog I’ll walk you through:
• What are Zoned Storage Devices and why this technology is being adopted
• SMR HDDs and Zoned Namespaces SSDs
• Data infrastructure – what it takes to adopt Zoned Storage
• The Zoned Storage Initiative
What are Zoned Storage Devices?
In a nutshell, Zoned Storage Devices are block storage devices that have their address space divided into zones. ZSDs impose unconventional writing rules: zones can only be written sequentially and starting from the beginning of the zone. In addition, data within a zone cannot be arbitrarily overwritten.
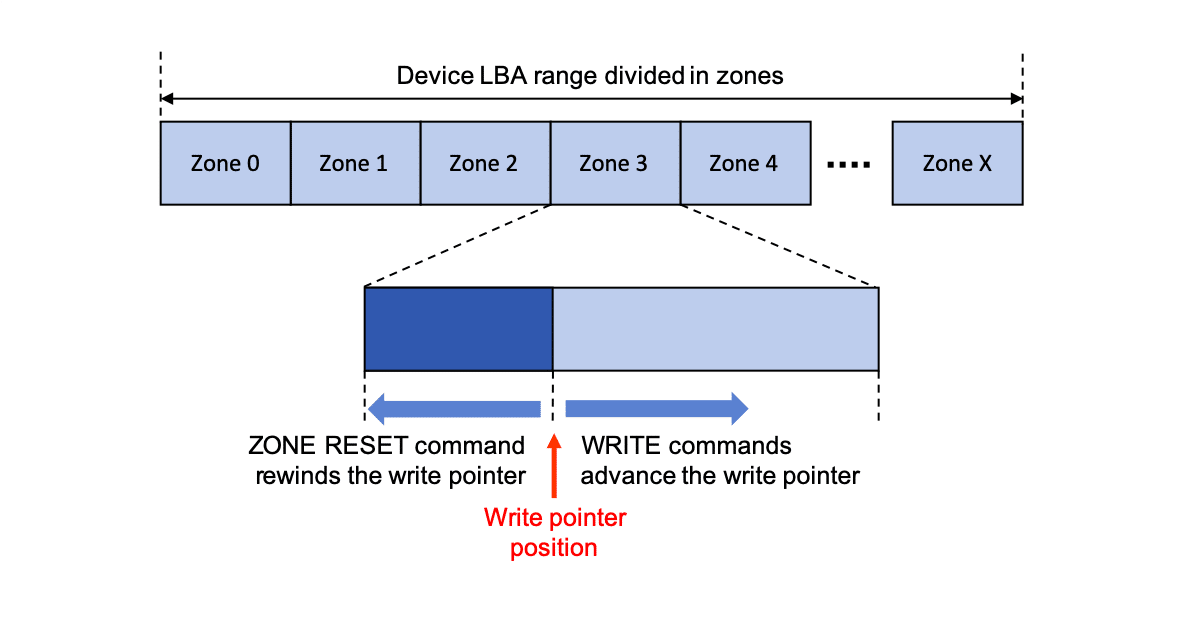
The only way to overwrite an already written zone is to reset the zone write pointer, effectively deleting all the data in the Zone, and to restart writing from the beginning of the zone. Reading data, on the other hand, is largely unrestricted and the data can be read in the same manner as on traditional storage devices.
The Zoned Storage Device concept is standardized for storage devices as:
• ZBC: Zoned Block Commands in T10/SAS
• ZAC: Zoned Device ATA Command Set in T13/SATA
• ZNS: Zoned Namespaces in NVMe™ (Technical Proposal in progress)

Why Zoned Storage?
The motivation for Zoned Block Device technology is at-scale data infrastructure efficiency. Thanks to this technology, larger capacity devices can be used in a more cost-effective way that allows for efficient system-wide performance management.
The Case for SMR
Over the last few years, Shingled Magnetic Recording (SMR) technology has been introduced in Hard Disk Drives (HDDs) to enable increased areal density and larger capacities and cost-effectiveness for HDDs. In SMR, unlike conventional recording, tracks are written in an overlapping manner. This allows tracks to be more tightly packed and hence achieves a higher density of recording.
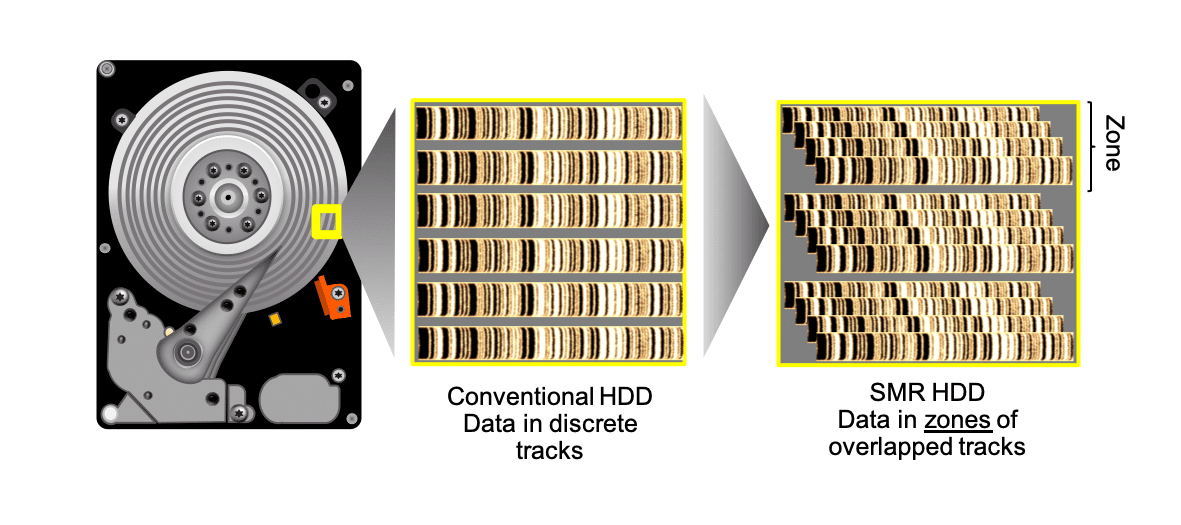
However, once the tracks are overlapped, they cannot be written independently. In order to manage the recording, the disk surface is divided into Zones with a gap left between Zones. This allows each Zone to be written and erased independently. Multiple approaches are possible to manage the recording restriction. The traditional approach assumes the device handles the recording constraint internally and expose a conventional interface to the host. Yet for large-scale systems, where performance and space utilization must be carefully managed, there are disadvantages for device-side localized management. Managing the complexity on the host side is almost a requirement for large storage systems and is the go-to choice for hyperscale data centers.
Host Managed SMR is standardized in INCITS T10/T13 as Zoned Block Commands (ZBC) and Zoned Device ATA Command Set (ZAC) for SAS and SATA respectively.

NVMe and Zoned Namespaces in Solid State Drives
For Solid-State Drives (SSDs), on the other hand, the restriction of having regions that can only be written sequentially and need to be erased before new data can be written to it is an inherent property of how flash storage operates.
When SSDs were initially introduced, they implemented an internal management system, called Flash Translation Layer (FTL), that would manage this recording constraint. The FTL allowed SSDs to be used in place of HDDs without the need to immediately rewrite the storage software stack. The local management inside the SSD creates some inefficiencies, however. In particular, there is:
• Write Amplification: To manage the constraints of not overwriting data, the SSD has to internally move data around to reclaim unused data locations, this is called Garbage Collection (GC). The GC process causes multiple writes of the same data (hence the term Write Amplification) creating further wear to the Flash media and reducing the life of the SSD.
• Over-Provisioning: Extra space (in some cases as large as 28%) has to be reserved for moving data around for garbage collection and to improve its efficiency.
• Large DRAM requirement: To maintain the FTL logical-to-physical mapping, a large amount of DRAM is needed in the device. Note that the amount of DRAM required increases with the size of the device.
• QoS variability due to the garbage collection kicking in at any moment without explicit control from the host software.
These inefficiencies were acceptable when SSDs were first introduced because the software stacks and interfaces were designed for HDDs, and their response times were much larger. The enhancement in performance constituted a good trade-off.
With time, however, the industry has moved to create more efficient interfaces and software stacks that can take advantage of the inherently lower latency and higher bandwidth of Flash. In particular, the Non-Volatile Memory Express (NVMe) interface specification was created, and the corresponding low overhead software stack developed.
The status in the industry today is that the local optimizations that have evolved in the SSD FTL have now become detrimental to at-scale data infrastructure deployments; in particular, a desire has emerged from many customers to enable a managed sequential workload align with Flash erase blocks. In response to this, the NVMe organization is standardizing Zoned Namespaces (ZNS) that will allow the host to direct I/Os to separate workloads, and improves latency, throughput and costs efficiency by moving the bulk of management to the host.

Data Infrastructure – Adopting Zoned Storage
Zoned Block Devices deliver at-scale efficiencies, yet to take advantage of these new devices requires a heavy lift as they are not backward compatible. While traditional storage devices have no restriction on writes, Zoned Block Devices have the restriction that writes within a Zone must be sequential. The main consequence of this is that the software stack must be updated!
The first component that needs to be updated is the operating system. This is not a trivial task in modern multi-tasking operating systems running on multi-core & multi-socket servers, typical of data-center deployments. The Linux® community has applied substantial effort to support Zone Block Devices in general, and SMR in particular.
In addition to the Linux kernel support, there are a number of utilities and applications that support Zone Block Devices, such as fio, blktests and util-linux.
Linux Kernel and Zoned Block Devices
The Linux kernel work on zoned storage started back in 2014 with the most minimal amount of support incorporated into the 3.18 kernel. The first kernel release with functional ZBC/ZAC command support was kernel 4.10 in early 2017. The support has continued to improve, and the most recent kernels have device-mapper support as well as some filesystem support.
The picture below shows a high-level depiction of the structure of the Linux kernel and how Zone Block Devices can be integrated alongside legacy conventional block devices. The support in the Linux kernel was introduced through the modification of some existing components, the introduction of new interfaces, such as the ZBD Interface in the Block Layer, as well as introduction of new components, such as the dm-zoned device mapper.
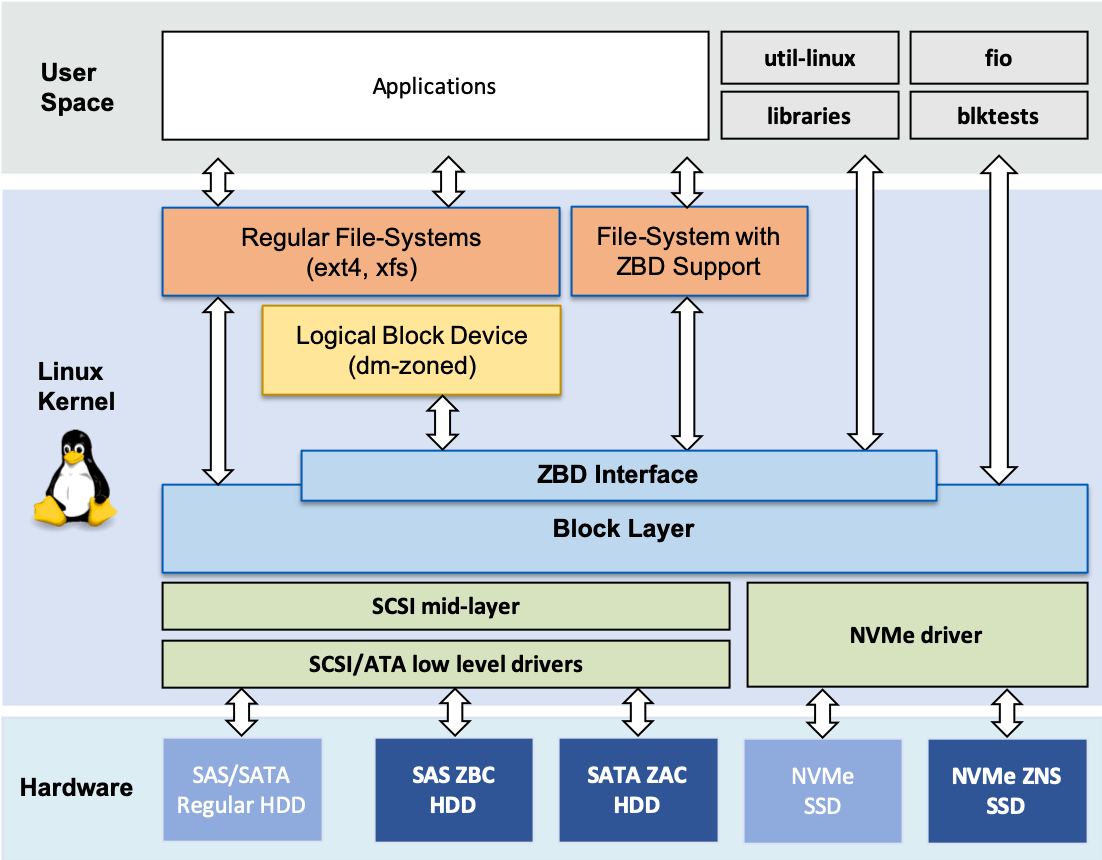
As the picture shows, there are many paths by which a data infrastructure deployment can make use of Zone Block Devices. For example: (i) Using a legacy filesystem with the dm-zoned device mapper, (ii) Using a filesystem with native ZBC support, (iii) Using ZBD aware applications that talk directly to Zone Block Devices through user space libraries, such as libzbc, etc.
Zoned Storage Initiative – Facilitating Wider Application Support and Adoption
Despite the advances made by the open source community to support Zone Block Devices, there is still some effort required by data infrastructure engineers and application developers to make use of this technology, such as finding out what level of support exists in each of the Linux kernel releases, or which versions of applications have the needed support and what is the required kernel version for them to work.
The Zoned Storage Initiative was launched in part to address this problem and to facilitate wider application support for Zoned Storage technologies. You can go to ZonedStorage.io to learn more about Zoned Storage technologies and adoption of ZNS SSDs and ZBC/ZAC SMR HDDs. There you will find information on:
• Zoned Block Devices
• Getting Started Guides
• Linux Kernel Support and Features
• Application and Libraries
• Benchmarking
• System Compliance Tests
Using this platform, infrastructure engineers and storage application developers now have a centralized location to get all the information and resources needed to make use of Zoned Storage Technologies.
Learn More About Zoned Storage
• Visit ZonedStorage.io
• Read about Enabling the Zettabyte Age with Zettabyte Storage


