

Log-Structured Merge-Tree and Zoned Namespaces can offer a better way to drive largescale databases and make QLC SSDs viable for data-intensive workloads. Here’s everything you need to know.
The storage industry has made tremendous progress since the inception of data center SSDs based on SLC (single-level cell). The transition of SLC to MLC (multi-level cell with two bits per cell), and MLC to TLC (three bits per cell) has allowed for improved storage density at a lower price point. Now we’re looking at the next transition of TLC to QLC (so-called quad-level design with four bits per cell) but it requires us to address the tradeoffs between a higher bits per cell and write endurance.
In this blog I’ll look at one way to solve the conundrum of data center SSDs based on QLC, and how to address the write endurance aspects of QLC through the storage engine and writing technology. This is particularly important for those working on next-generation workloads or iterations in database technologies with very larger data sets who are concerned with improved TCO.
Data Center Storage, a New Chapter
Data center storage is on the cusp of technological improvement. Let me frame this by asking what is the fastest way to write data at the lowest cost for cloud-based applications?
There are two important aspects of the question:
A) writing speed
B) cost of writing. And this is where the new chapters in flash-based data center storage begins.
Data Structure for Cloud-Based Applications
Sequential I/O or large-block sequential data streams may be an easy answer when addressing the question of the speed of writing. A quick example is that appending/logging a document is relatively faster when compared to search in which you add the text, read the existing text, delete the unwanted part, and then write the new text. This is just comparing the number of steps required, and the associated time to finish the writes.
On the other hand, the cost of writing, particularly for flash-based media, stems from two parts:
1) storage media cost
2) storage write amplification.
Solid-state storage can continue to shift from MLC > TLC > QLC to maintain media cost erosions but the lower number of P/E (Program/Erase), aka endurance cycles, of QLC media restricts its widespread adoption due to concerns in heavy-write workloads.
One way of addressing this is through the “Sequentializing” of data writes, matching the physical SSD media requirements. This helps reduce storage write amplification to the lowest level and almost all available writes go to the user instead of NAND device management. Even in extreme performance SSDs, random access is slower than sequential access. As such, sequential writes are better for both higher write performance and lower write amplification. Combined with QLC benefits, we answer the questions of speed, storage media costs and storage write amplification (endurance).
Now, the question then turns to enablement. How do you actually implement these concepts into a QLC-based product to deploy in your data center?
Application Storage Engines
The world of data center storage has many different storage engines, among them two main engines:
A) B-tree (BT)
B) Log-structured merge-tree (LSM-Tree)
BT keeps data sorted and offers faster search/queries, lower latency reads, insertions, and deletions.
LSM-Tree keeps data indexed and good for high degree of write activities or changes. LSM-Tree algorithms begins data placements in the upper hierarchy of storage and shifts them to the other media, including low endurance media, once data stabilizes. See Figure #1. Therefore, LSM-Tree enables higher write performance and lower the cost of writing.
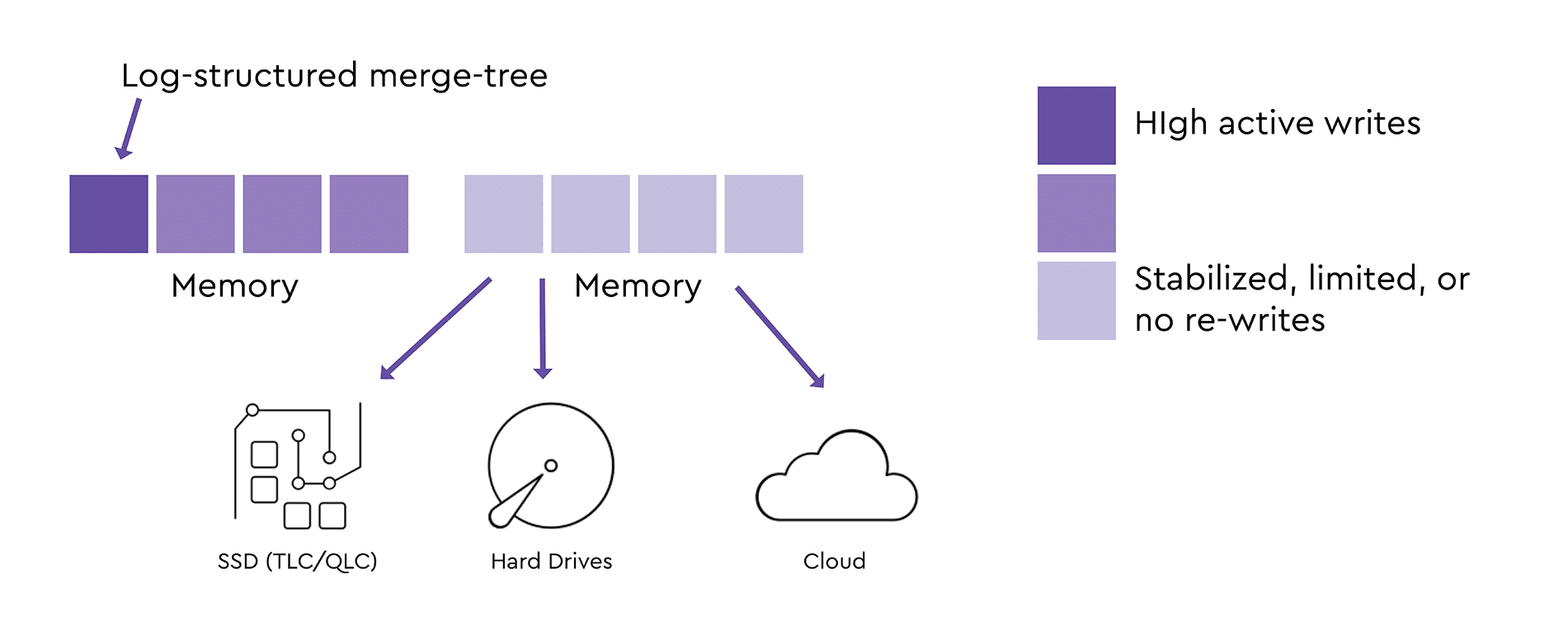
Connection with Zoned Storage
Zoned Storage adds more value in addition to what LSM-Tree engines offer. ‘Zones’ are logical construct mapped onto storage LBA space. In the case of NVMe™ Zoned Namespace (ZNS) SSDs, the namespace LBAs divided into several zones. ZNS SSDs only allow sequential writes. The write pointer does not move, so if any rewrite is required, an entire zone has to be rewritten.

Figure #2 compares writing in a standard SSD vs. ZNS SSDs. Now let’s bring this back to LSM-Tree.
As shown in Figure #1, LSM-Tree engines start sequential and hierarchical writing once data is relatively stable. ZNS SSDs go an extra step and allow applications to write in their specific allotted zoned namespaces. The ZNS SSDs give flexibility to application to place data in their respective zoned namespaces, allowing for intelligent data placement with defined control (for example to dedicate zones to different workloads or types of data). This is something not possible with standard SSDs even with LSM-Tree storage engines.
Furthermore, when standard SSDs delete data, that triggers garbage collection to re-claim free blocks. ZNS SSDs on the other hand have zone boundaries aligned with NAND physical boundaries so when the data is deleted, it frees up the zone and makes them available for new write activities. This can be seen in Figure #3 (click to animate).

In zoned SSDs the host owns and runs garbage collection and wear levelling at the system level and pushes the drives to focus more on application demand IOs. This results in higher and much more predictable I/O performance with the NVMe 1.4 release.
On a cost perspective as ZNS SSDs reduce NAND overprovisioning, this frees up capacity for more data storage resulting in an effective lower $/GB when compared to conventional SSDs. And as both LSM-Tree engine and ZNS SSDs operate on large block sequential IOs it allows to reduce logical to physical address granularity and hence requires lower DRAM footprint on the drives. This, too, gives ZNS SSDs another cost optimization as compared to standard SSDs.
The net effect – while LSM-Tree engine only offers large block sequential IOs and lower storage/write amplification, ZNS SSDs cover more ground offering to:
1) Reduce storage write amplification
2) Lower DRAM footprint
3) Lower overprovisioning through host managed drives that require no drive-level garbage collection, or wear leveling
4) Improved I/O performance and predictability
5) Accelerate QLC adoption with LSM-Tree storage engine for significant storage density advantage of four bits per cell
Database Data Center Use Cases
Databases have already realized the value of large block sequential writes to improve write performance and reduce storage/write amplifications. LSM-Tree engine is now default in some NoSQL databases such as Apache Cassandra®, Elasticsearch® (Lucene), Google Bigtable, Apache HBase™, and InfluxDB. The RocksDB LSM-Tree implementation called MyRocks replaces the InnoDB engine while MongoDB®’s new default engine comes in BT and LSM-Tree configurations.
Since these applications are leveraging LSM-Tree engine, they are good leads for ZNS SSD adoption. Beyond databases and primary storage, there are also several interesting ZNS + LSM-Tree engine use cases in large block sequential read caching for edge computing.
Next Steps
Data Center architects, application stack stakeholders, and those who have a stake in data monetization can learn more about Zoned Namespaces SSDs on the Zoned Storage resource page and zonedstorage.io
Zoned Storage is an open source initiative. It’s going to take a collaborative effort with the broader software and hardware community for the full implementation of QLC-based data center SSDs for the data center use cases of predictable and scalable databases. The journey has begun.

