

Last year, I traveled to China, Europe and the US to interview and meet with deep learning data scientists, data engineers, CIOs/CTOs, and heads of research to learn about their machine learning data challenges. This is the first of a four-part series summarizing my learnings and the data policies I’ve recommended.
Deep learning is a part of machine learning that focuses on the algorithm and accuracy of modelling. In this blog, I will take a closer look at the data flow in the end-to-end machine learning pipeline.
To help organizations understand how to build an optimized data infrastructure for machine learning, they need to understand how their data is served, accessed and processed at every step.
I’ve found it extremely helpful to map out a typical machine learning pipeline step by step to look at data size, access patterns and file system across the entire pipeline.
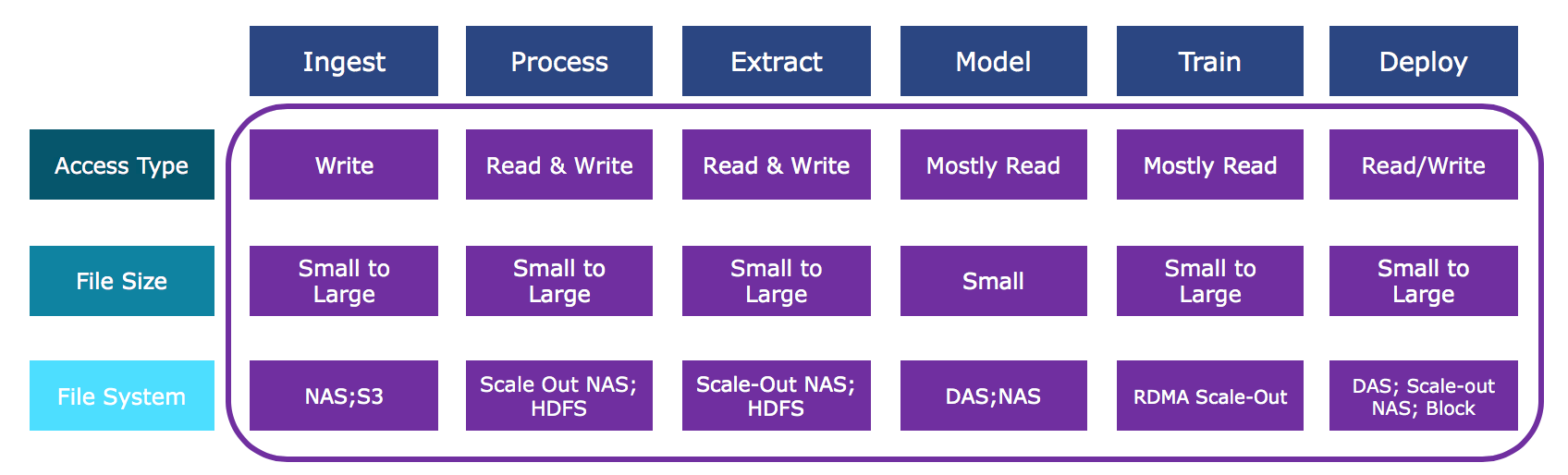
Ingest – What Kind of Data Are You Collecting?
Ingest can see all types of data and use cases across many industries and applications. For example, you may find ingest data to be really small if it is coming from IoT sensors. This type of data will include a time series and corelated data captured at sub-second frequency. In contrast, if the data is captured from a satellite in orbit, we’ll see use cases where terabytes of compressed image data are sent to earth only once a day.
Another example would be autonomous driving, where data can include time series type of sensors in the car as well as large high-definition image/video files. Yet regardless the size of data, the access pattern for ingest is always write only. IOPS is one of the most important ingestion requirements.
Process – Heavy Workloads
For the processing stage, data will be annotated, cleansed, and correlated to prepare for feature extraction. We see the read vs write ratio is most often at 1 to 1. This requires high performance and high capacity, with the ability to read, process, and write petabytes of data critical. At this scale, parallel file systems running on fast storage, like all-flash NVMe™ storage servers leveraging 100 GE networking interfaces, are often deployed to support compute servers and achieve results faster.
Extract – An Iterative Read/Write Workflow
What features you are working to extract depend on the hypothesis and will usually require further validations in model training. Modelling and feature extraction are highly iterative until the hypothesis is finalized. In order to extract features, you’ll need to continuously read from the petabytes of processed data and write terabytes of feature data. The read and write access pattern may take place on a single infrastructure, particularly in advanced hyperscale machine learning projects, and then extracted features that are much smaller will be loaded to a GPU platform.
Model – Working with Small, Different Data Sets
Data scientists use subsets of extracted data to test their hypothesis. They experiment with different datasets and modify their algorithm in order to improve the data model accuracy. Only when they think the model has proven their hypothesis and the models reach the expected accuracy, these models are going to be trained with large dataset to further improve the accuracy. So initially, this step of the workflow will see a small dataset using mostly read access pattern and only a few write cycles for the model output.
Train – the Role of the GPU
When a model is developed based on the hypothesis, it time to train the model. This is where the deep learning is applied. In this step, large datasets are used to train the model. Most often, a cluster of GPU servers with high network bandwidth are deployed to speed up the training time. Because GPU, memory, and networking are expensive resources, being able to feed the GPUs is critical. Fast storage infrastructure along with the purpose-built file system should be considered to achieve higher return of the GPU environment.
Deploy
When a trained model is deployed, it is going to take a new dataset to produce the required result/answer. If it is inference, the answer can be a classification, tagging, or recommendation. Whether or not the answer is stored, it will be a much smaller dataset when comparing to the original one used. There are cases of generative machine learning models which are used to generate new things based on existing content like images, art or music in a particular style. In these deployments, you’ll find the read and write ratios as 1:n.
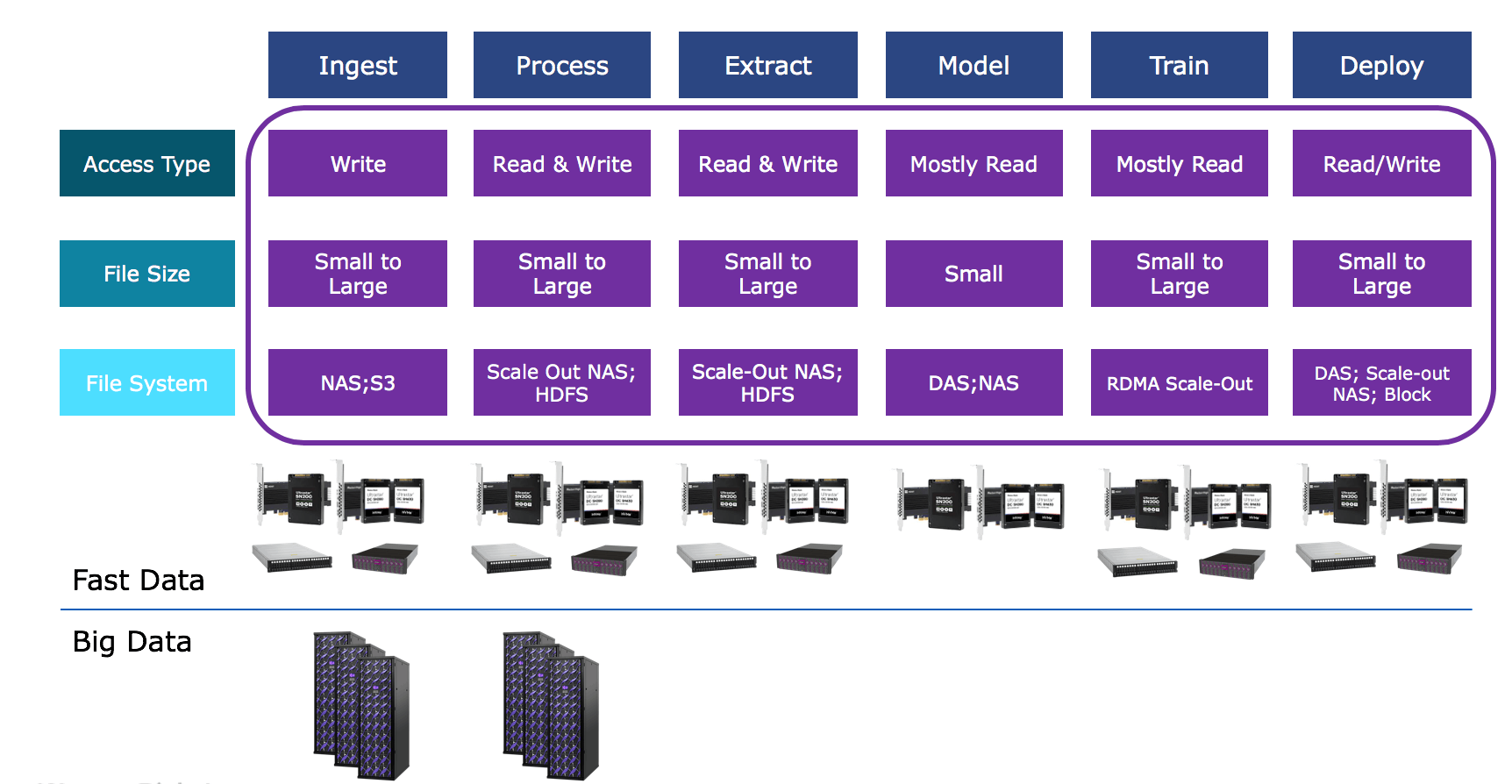
Big Data vs. Fast Data
As you approach building the infrastructure for machine learning, the simplest way to approach your deployment is by understanding where your big data needs are vs. fast data.
Critical steps such as Ingest, Process, Train, and Deploy will require fast data. This could mean leveraging flash devices, including new NVMe solutions, all-flash systems, or Software-Defined Storage based on fast flash storage servers.
Big Data is a component of all stages, either as an archive repository or digital repository for the petaybtes of data you are drawing from. You can leverage high-capacity hard drives, hybrid storage servers in a Software-Defined Storage configuration, or low-cost cloud object storage systems.
Here is one example of what the pipeline would look like from a data infrastructure perspective:
Learn More at Open Compute Summit
If you’re at Open Compute Project (OCP) this week in San Jose, make sure to stop by booth #D14 in the main exhibit hall, where we will host demonstrations about cutting-edge technology that can help answer your machine learning and other big data and fast data needs.
Particularly, you will be able to learn about the OpenFlex™ Composable Infrastructure, SMR-drive Innovation, Cost-Optimized All-Flash NVMe™ HCI for the Hybrid Data Center, and the latest on Dual Actuators technology. You can also learn more in our two speaking sessions: “The TCO of Innovation in the Data Center” and “Accelerating the Evolution of Data Storage”.
Up Next: Data Challenges
In my next blog, I will cover data challenges from the ingest and process stages, followed by data lineages challenges from the Process, Extraction and Training steps. The last blog of the series will be dedicated to Deployment. Make sure to subscribe below to get notifications when new blogs are published.

